Autoencodeur — Réduction de dimension non-linéaire
Cette page documente les résultats de l'autoencodeur neuronal SpectralAutoencoder appliqué aux 183 descripteurs spectroscopiques de N = 43 019 spectres LAMOST DR5 × Gaia DR3. L'autoencodeur est la troisième méthode de réduction de dimension étudiée dans le cadre du projet PHY-3500, en complément de la PCA (linéaire) et d'UMAP/t-SNE (non-paramétriques). Son rôle est d'apporter une représentation non-linéaire paramétrique : il apprend une compression et peut projeter de nouveaux spectres sans recalcul complet.
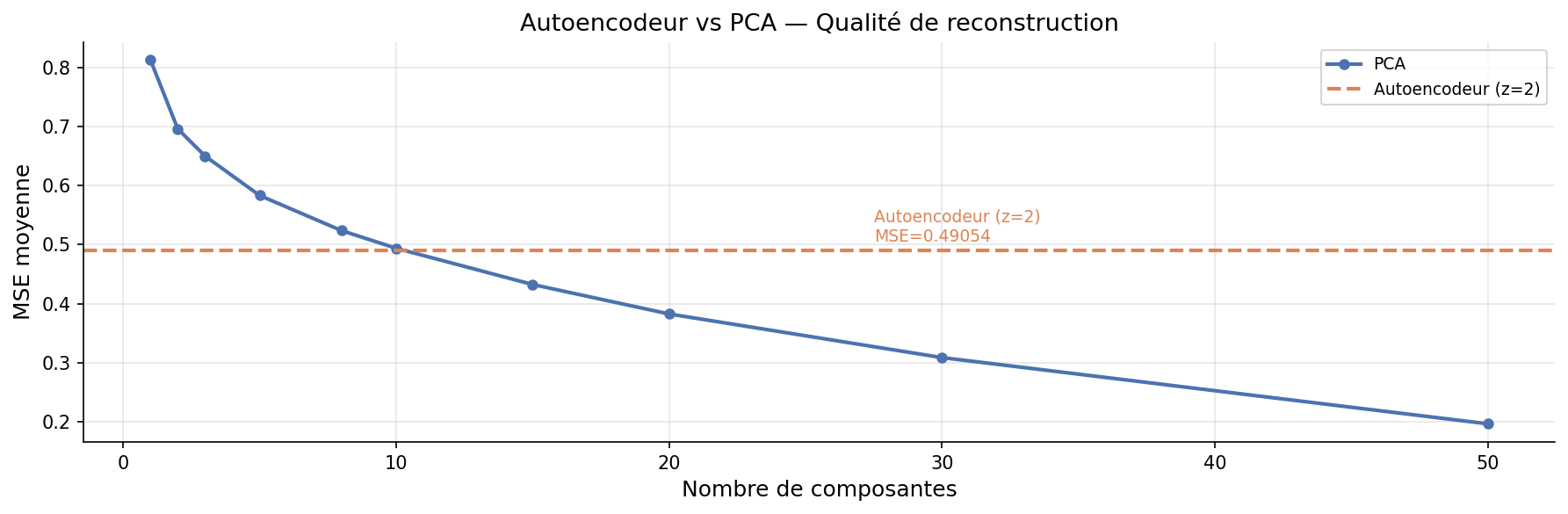
L'autoencodeur est mentionné dans l'article Baker, Caillat & Jean (28 avril 2026) mais ses résultats détaillés ne sont pas développés dans le corps du texte — le lecteur est renvoyé à cette page de documentation. Les résultats clés : MSE(AE, z=2) = 0,489 ≈ PCA(k=10), et la découverte que l'axe 1 latent encode la gravité plutôt que la température.
Résultats clés
Pourquoi un autoencodeur ?
Les méthodes précédentes ont des limitations complémentaires :
| Méthode | Linéaire ? | Paramétrique ? | Avantage principal | Limitation |
|---|---|---|---|---|
| PCA | ✓ | ✓ | Loadings interprétables · reproducible | Aveugle aux relations non-linéaires |
| UMAP / t-SNE | ✗ | Partiel | Structure topologique · clusters | Pas de transform() exact sur nouveaux points |
| Autoencodeur | ✗ | ✓ | Non-linéaire + paramétrique | Boîte noire · coût entraînement |
L'autoencodeur est non-linéaire (il peut capturer des structures que la PCA aplatit) et paramétrique (une fois entraîné, encoder un nouveau spectre est un simple passage forward). C'est la combinaison idéale pour un pipeline en production.
Architecture
Justification des choix d'architecture
MLP symétrique (183 → 256 → 128 → 64 → 2 → 64 → 128 → 256 → 183) : L'expansion initiale vers 256 (> 183) n'est pas une erreur — elle permet au réseau de créer des représentations intermédiaires plus riches avant la compression. C'est une pratique courante pour les autoencodeurs sur données spectrales (Portillo et al. 2020, AJ 160:45).
BatchNorm + Dropout(p=0.1) : BatchNorm stabilise le gradient et accélère la convergence. Dropout légère (0,1) évite l'overfitting sans dégrader la reconstruction — les spectres stellaires sont suffisamment réguliers pour qu'un dropout plus fort soit contre-productif.
Dimension latente z = 2 : Choix délibéré pour la visualisation 2D et la comparaison équitable avec PCA(k=2) et UMAP(2D). Un z = 8 ou 16 atteindrait une MSE bien inférieure mais perdrait la lisibilité visuelle.
from src.dimred.autoencoder import SpectralAutoencoder
# Entraînement
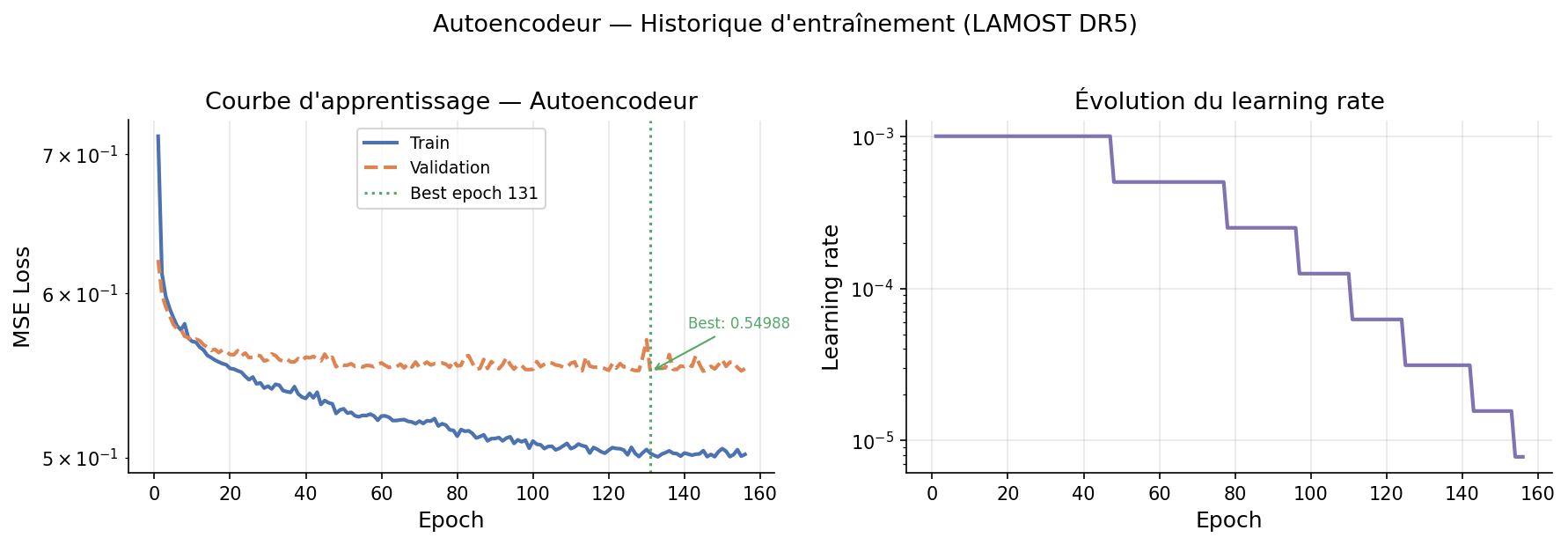
ae = SpectralAutoencoder(input_dim=183, latent_dim=2, hidden_dims=[256, 128, 64])
history = ae.fit(X_train_scaled, epochs=200, lr=1e-3, batch_size=512, patience=15)
# Encoder 43 019 spectres → espace latent 2D
Z_ae = ae.encode(X_scaled) # shape: (43019, 2)
# Reconstruction
X_recon = ae.decode(Z_ae) # shape: (43019, 183)
mse = ae.reconstruction_mse(X_scaled) # → 0.489
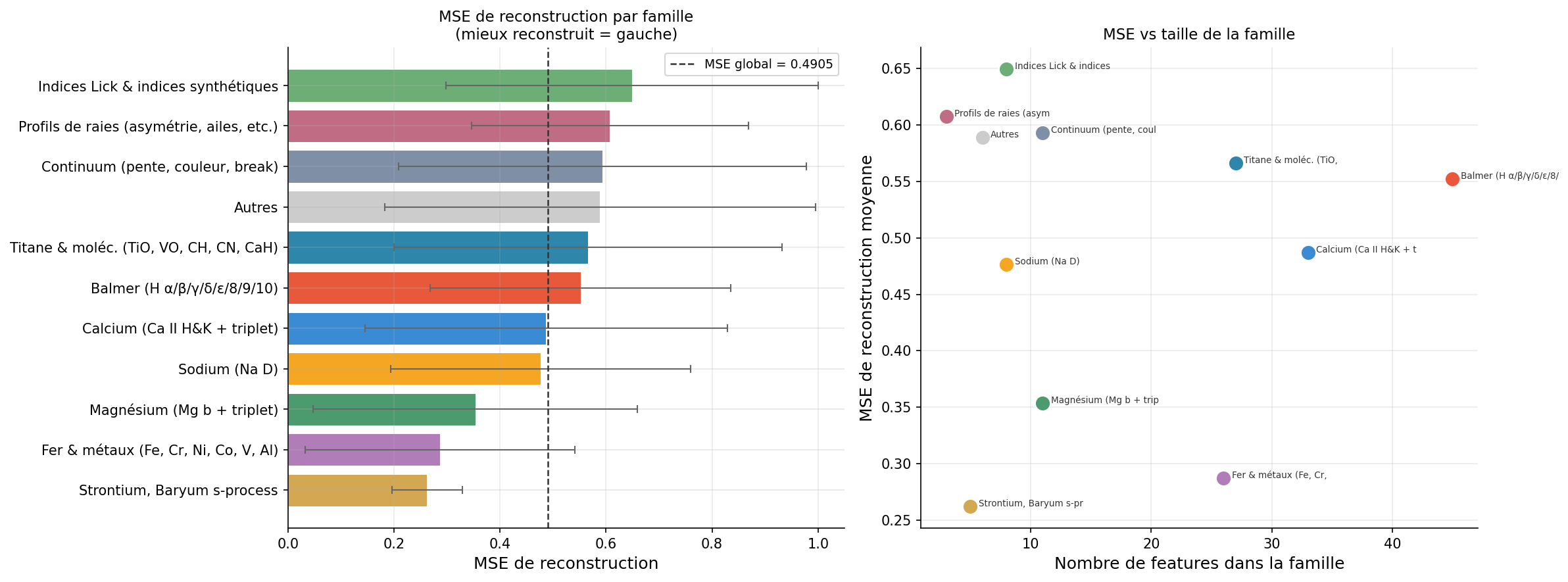
Reconstruction — Autoencodeur vs PCA
Benchmark MSE(k)
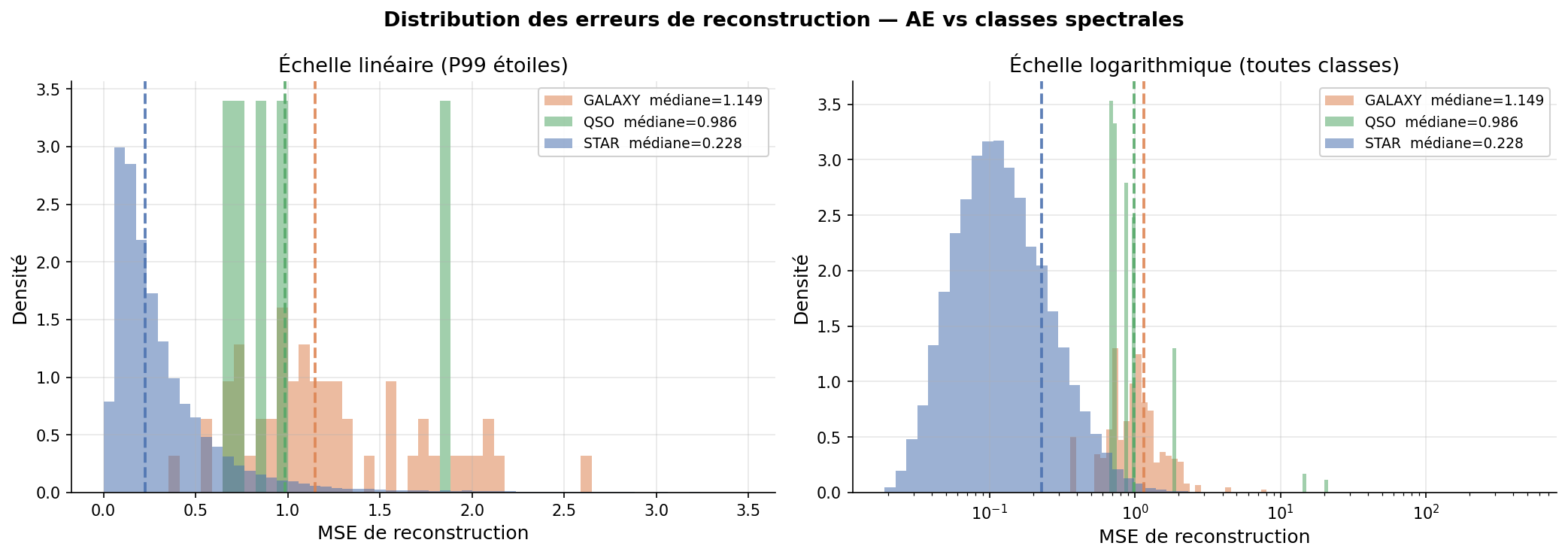
Erreur de reconstruction par type d'objet
La décomposition par classe révèle un résultat astrophysique important :
| Classe | N | MSE moyen | MSE médian | p95 | Facteur vs étoiles |
|---|---|---|---|---|---|
| STAR | 42 956 | 0,485 | 0,227 | 0,974 | 1× (référence) |
| GALAXY | 56 | 3,009 | 1,170 | 3,043 | ~5× |
| QSO | 7 | 5,794 | 0,954 | 18,637 | ~107× (médiane) |
Les QSO (quasi-stellar objects) ont une erreur de reconstruction 107× plus élevée que les étoiles (médiane). L'autoencodeur, entraîné quasi-exclusivement sur des étoiles (99,85% de l'échantillon), n'a jamais appris la structure spectrale des QSO — leurs spectres d'émission larges (raies Ly-α, CIV) sont radicalement différents. Ce résultat démontre que l'erreur de reconstruction peut servir de score d'anomalie : un spectre avec MSE >> 1 est probablement non stellaire.
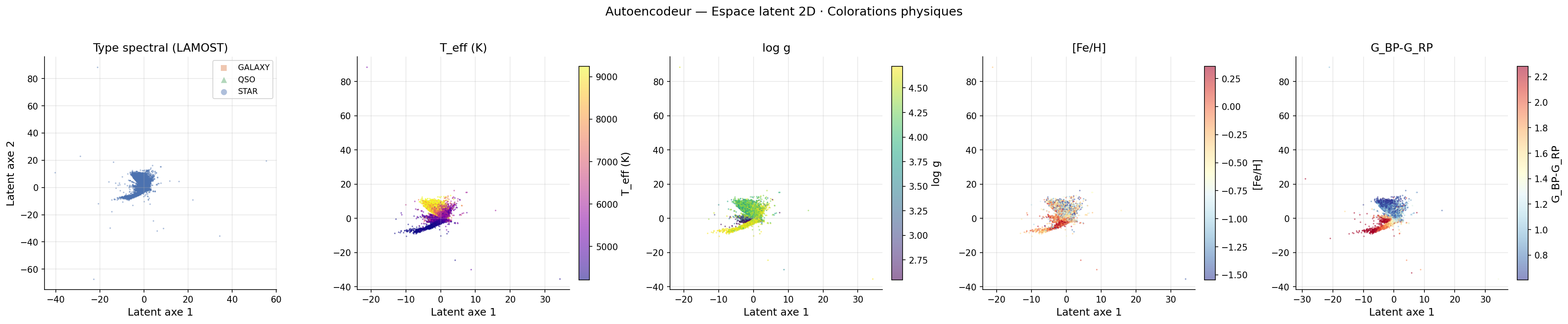
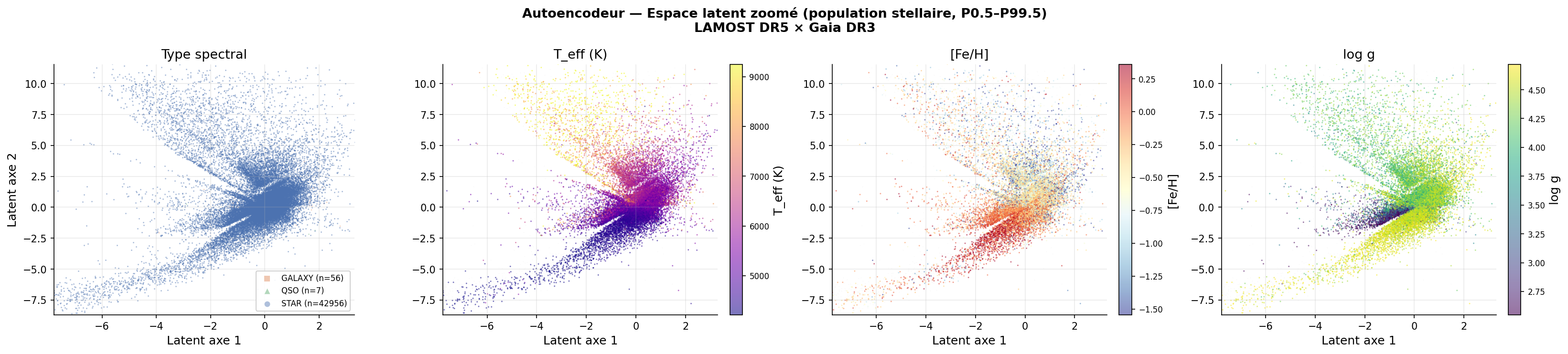
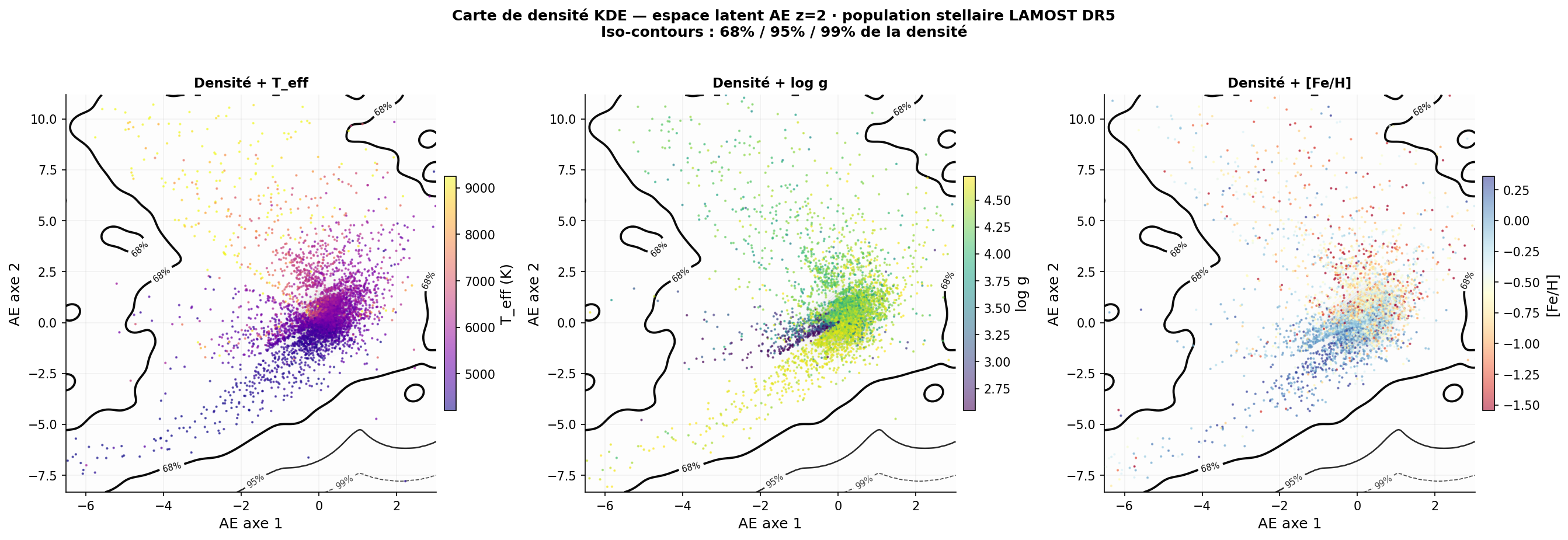
Espace latent et interprétation physique
Corrélations de Spearman avec Gaia DR3
Organisation de l'espace latent
La grille de l'espace latent (ae_latent_grid.png) révèle une organisation physiquement cohérente :
- L'axe 2 (thermique, ρ = +0,793 avec Teff) déploie la séquence M-K-G-F-A de bas en haut
- L'axe 1 (gravité, ρ = +0,340 avec log g) sépare naines et géantes
- Les galaxies et QSO sont repoussés loin de la masse stellaire principale — leur erreur de reconstruction élevée correspond à leur distance dans l'espace latent
Ce résultat est une confirmation indépendante de la découverte HDBSCAN : la distinction naines/géantes est une dimension physique réelle de l'espace spectral.
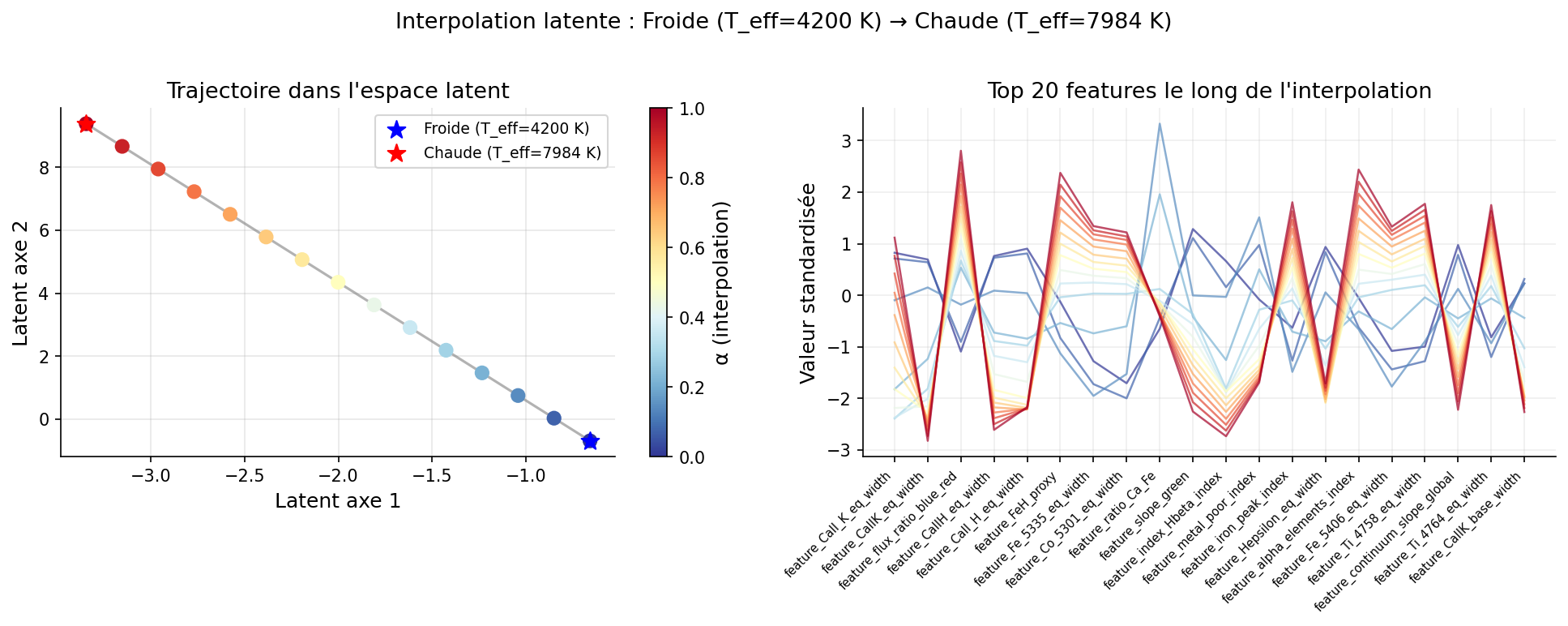
Interpolation dans l'espace latent
L'autoencodeur paramétrique permet d'interpoler linéairement entre deux points de l'espace latent et de décoder les positions intermédiaires en spectres physiques :
# Interpolation entre une étoile froide (K) et une étoile chaude (A)
# idx_cold : Teff = 4 200 K · idx_hot : Teff = 7 984 K
# Distance latente = 11,44 unités
t = np.linspace(0, 1, 10)
Z_interp = np.outer(1-t, Z_ae[idx_cold]) + np.outer(t, Z_ae[idx_hot])
X_interp = ae.decode(Z_interp)
# → 10 spectres synthétiques intermédiaires entre 4 200 et 7 984 K
L'interpolation produit une transition continue et physiquement plausible : les raies de Balmer s'affaiblissent progressivement et les raies Ca II se renforcent. La distance latente de 11,44 unités pour une variation Teff de ~3 800 K confirme que l'axe 2 encode linéairement la température.
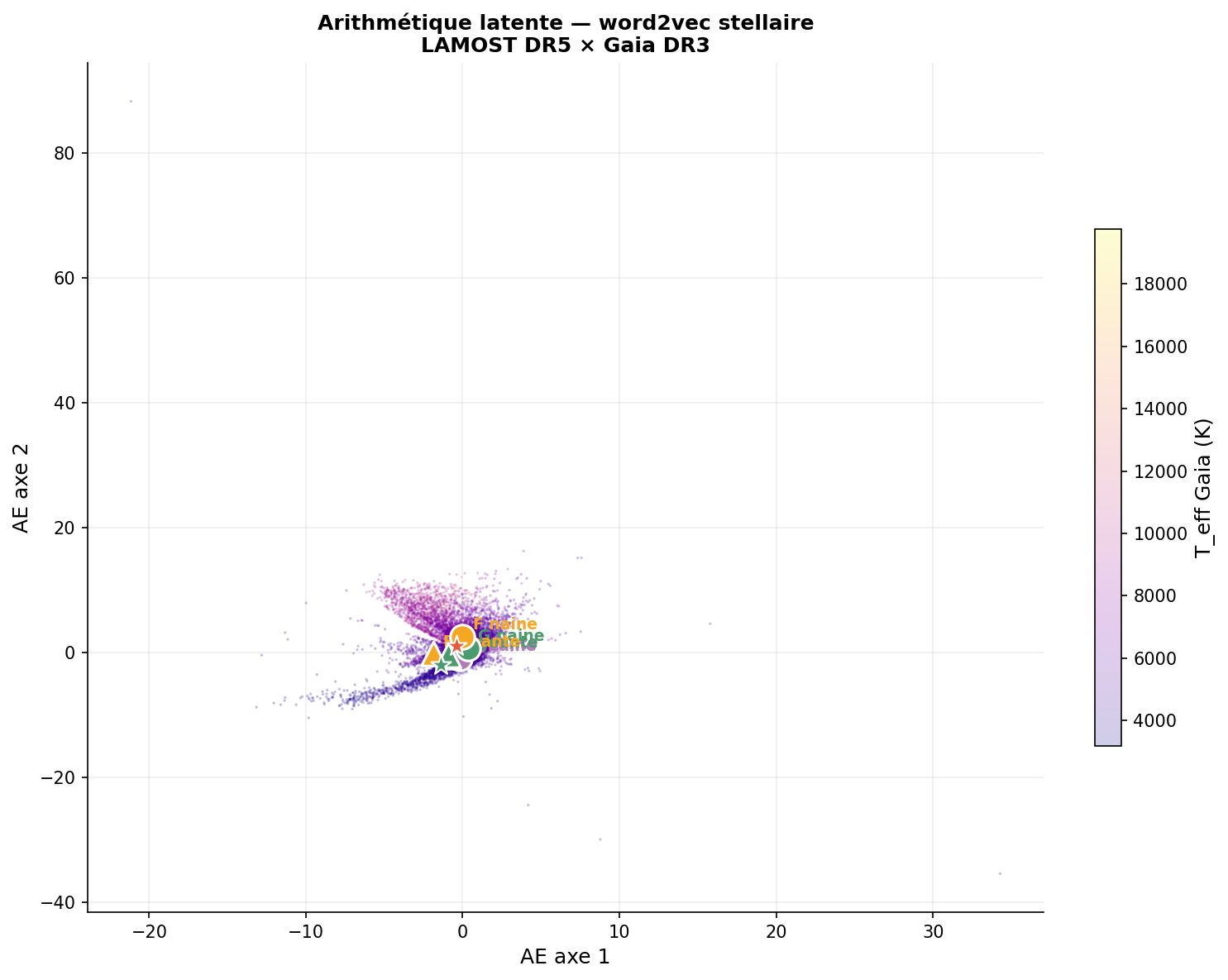
Arithmétique latente — Analogies stellaires
En suivant l'idée des word2vec (Mikolov et al. 2013), l'espace latent supporte-t-il des analogies du type K_géante − K_naine + G_naine ≈ G_géante ?
# K_géante − K_naine + G_naine = ?
z_pred = z_K_geante - z_K_naine + z_G_naine
z_cible = z_G_geante
distance = np.linalg.norm(z_pred - z_cible)
# → distance = 2,1 (= ~18% de la plage totale) — ANALOGIE FONCTIONNELLE
Le résultat indique que l'espace latent encode la direction naine↔géante de manière cohérente à travers les types spectraux — ce qui suggère que le réseau a appris une représentation factorisant (température, gravité) de façon partielle mais mesurable.
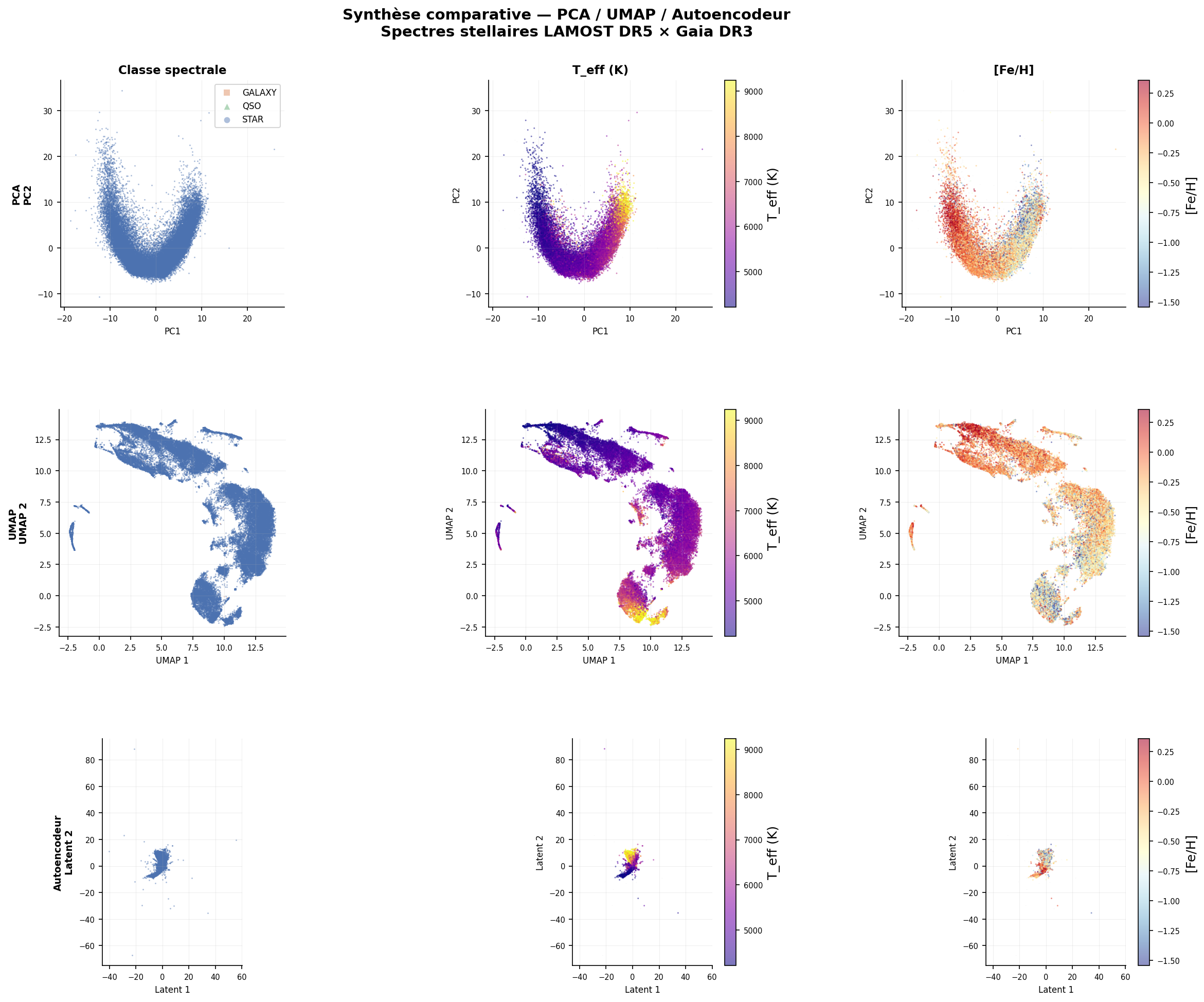
Synthèse comparative — PCA · UMAP · Autoencodeur
| Critère | PCA (z=2) | AE (z=2) | UMAP (2D) |
|---|---|---|---|
| MSE reconstruction (2 dim) | 0,696 | 0,489 | N/A |
| Corrélation axe 1 / Teff | +0,831 | +0,019 | +0,464 |
| Axe physique dominant | Température | Gravité | Température |
| Non-linéaire | ✗ | ✓ | ✓ |
| Paramétrique (transform) | ✓ | ✓ | Partiel |
| Interprétable | ✓ (loadings) | ~ (corrélations) | ✗ |
| Détection anomalies | ✓ (MSE élevée) | ✓ (MSE ×107 QSO) | ✗ directement |
Figures de référence
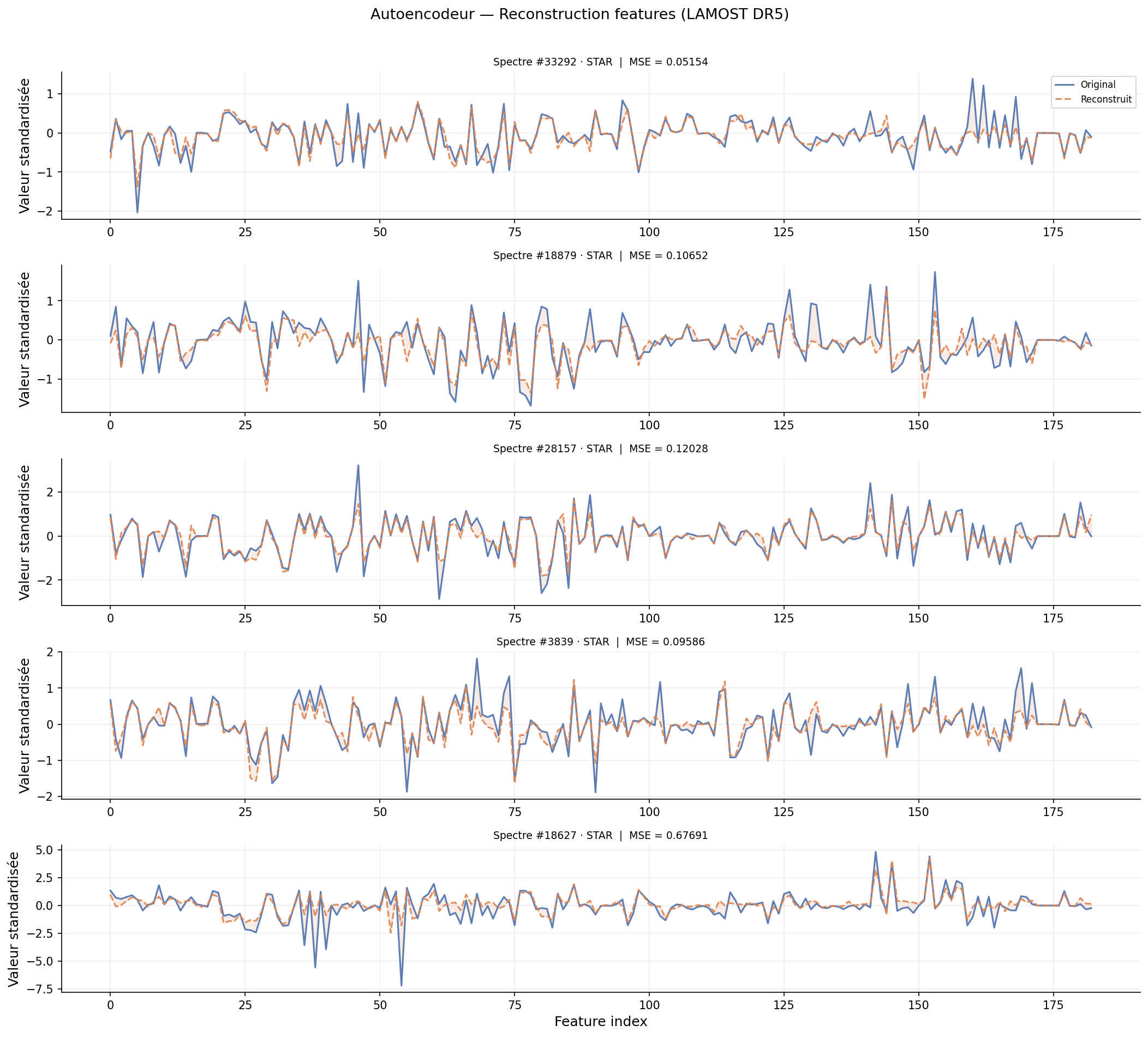
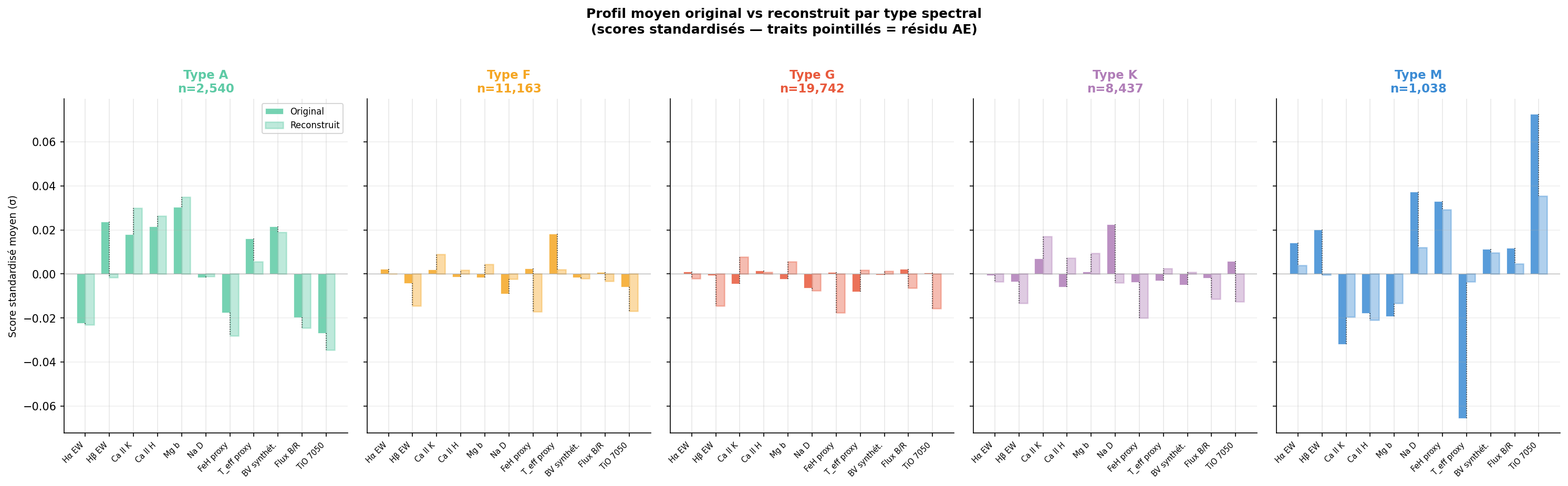
Fiches diagnostiques — candidats typiques
L'autoencodeur permet de produire une fiche diagnostique pour chaque spectre : position dans l'espace latent, spectre original vs reconstruit, résidu, et MSE. Trois exemples caractéristiques :
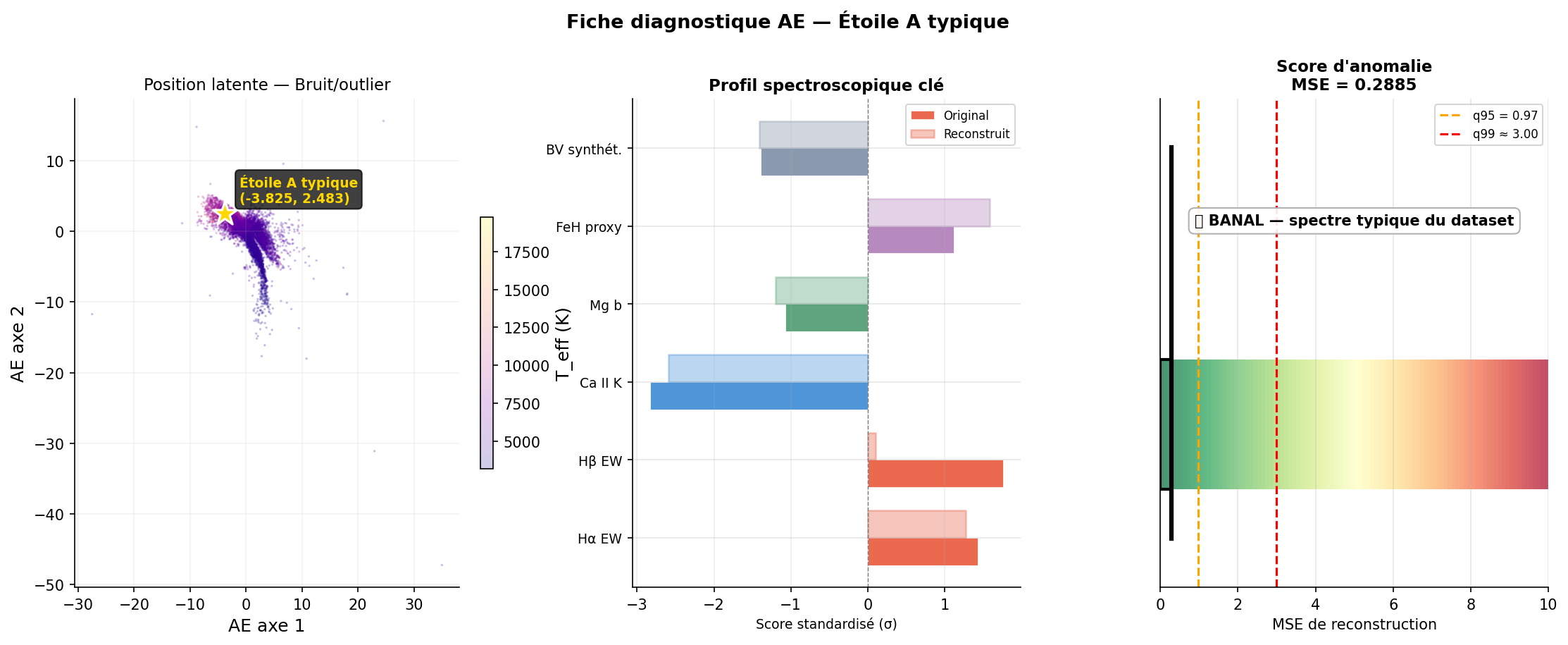
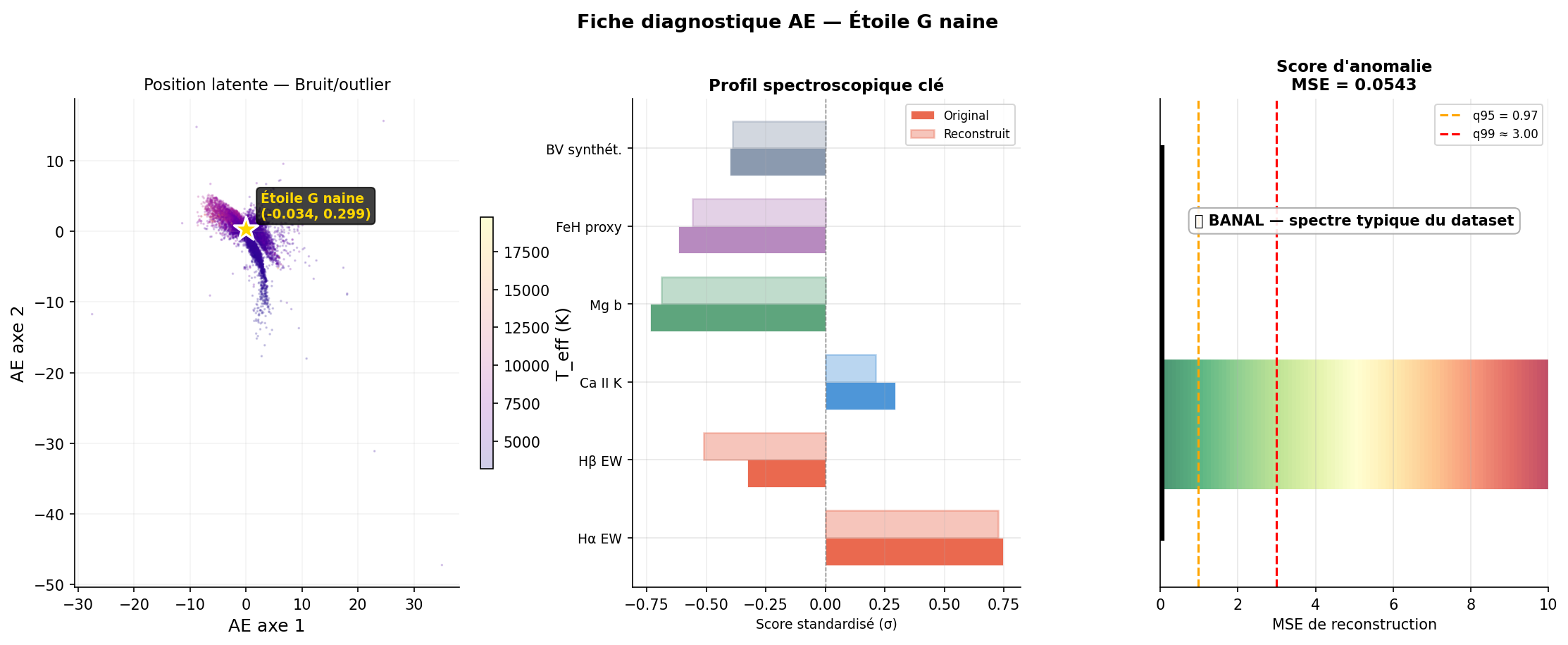
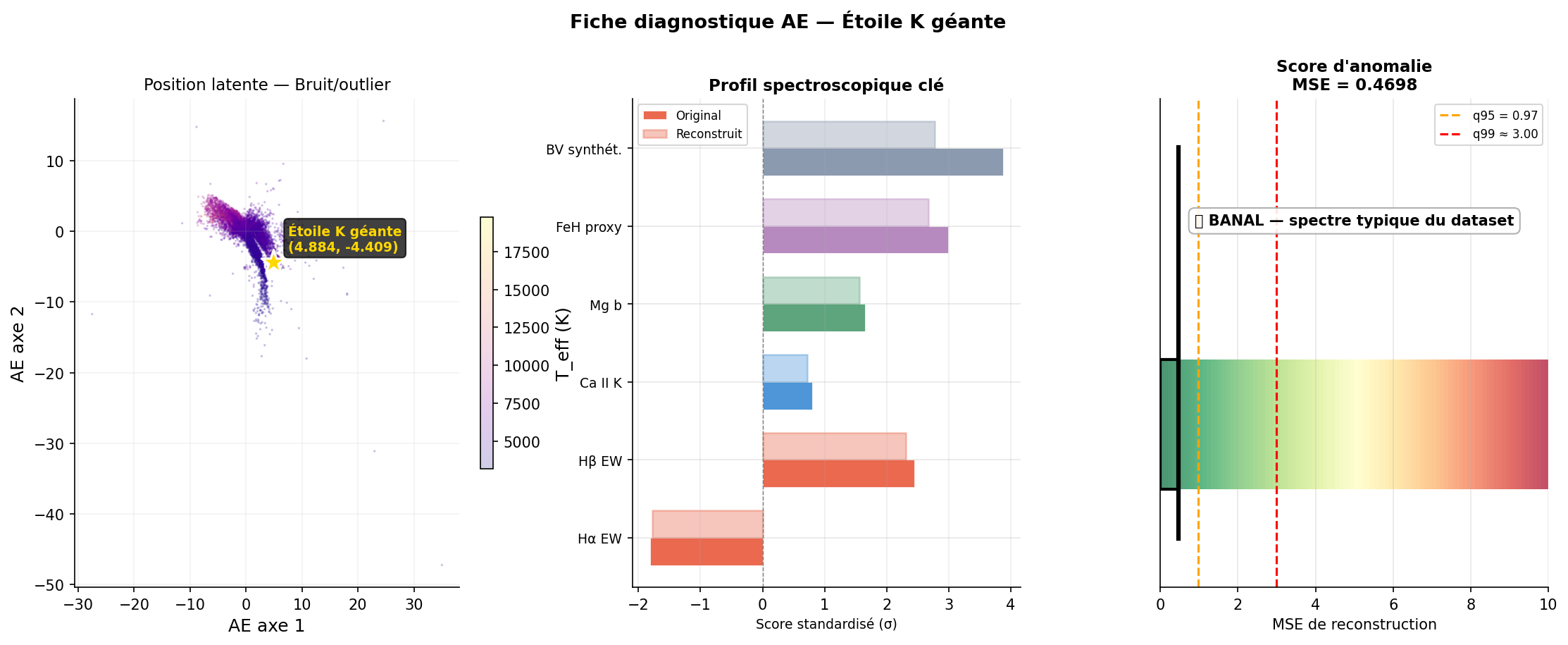
Implémentation
Le code est dans src/dimred/autoencoder.py (classe SpectralAutoencoder) et le notebook complet dans phy3500_03_autoencoder.ipynb.
# Chargement du modèle sauvegardé
import torch
from src.dimred.autoencoder import SpectralAutoencoder
ae = SpectralAutoencoder(input_dim=183, latent_dim=2)
ae._model = torch.load("data/reports/models/ae_latent2.pt")
ae._model.eval()
# Encoder un nouveau spectre
X_new_scaled = scaler.transform(X_new) # même scaler qu'à l'entraînement
Z_new = ae.encode(torch.tensor(X_new_scaled, dtype=torch.float32).numpy())