XGBoost — comparaison sur les mêmes 183 descripteurs
Cette page documente les résultats du classifieur supervisé XGBoost entraîné sur les mêmes 183 descripteurs spectroscopiques que ceux utilisés pour la réduction de dimension PCA/UMAP/t-SNE. Elle établit le lien entre l'approche non supervisée (structure émergente dans UMAP) et l'approche supervisée (classification avec étiquettes), démontrant que les deux convergent vers la même structure physique.
Résultats clés
Contexte et motivation
La conclusion de l'article PHY-3500 (Baker, Caillat & Jean, 28 avril 2026) ouvre sur cette perspective :
«Un classifieur XGBoost entraîné sur les mêmes 183 descripteurs atteint une précision équilibrée de 87 % sur cinq types spectraux (A, F, G, K, M), avec une confiance médiane de 96,3 % pour ses prédictions projetées dans l'espace UMAP. La cohérence géographique des prédictions XGBoost dans la projection confirme que le classifieur supervisé et les méthodes non supervisées de réduction de dimension capturent la même structure physique : les projections ne sont pas seulement des outils de visualisation, mais aussi des espaces de validation qualitative pour les modèles supervisés.»
Ce résultat est central pour AstroSpectro : il démontre que les 183 descripteurs spectraux purs (sans Gaia, sans ra/dec/redshift) sont suffisants pour une classification de haute performance.
Configuration expérimentale
Mode spectro_only=True
Ce résultat est obtenu en mode spectro_only=True du SpectralClassifier — c'est-à-dire en utilisant uniquement les descripteurs spectraux, sans aucune métadonnée observationnelle ni feature Gaia.
Les variables exclues par rapport au modèle complet :
ra,dec(coordonnées angulaires)redshift,seeing(conditions d'observation LAMOST)parallax,bp_rp,teff_gspphot,logg_gspphotet autres colonnes Gaia
Cette restriction garantit que le modèle apprend à classifier les étoiles à partir de leur physique intrinsèque uniquement — c'est la condition requise pour une publication scientifique rigoureuse et pour une application à des données sans cross-match Gaia.
Données d'entraînement
from src.pipeline.classifier import SpectralClassifier
clf = SpectralClassifier(
model_type="XGBoost",
prediction_target="main_class",
)
clf.train_and_evaluate(features_df, spectro_only=True)
Résultats de classification
Performance par classe — la séquence de Harvard
Confusion F/G — la frontière la plus délicate
La confusion principale du modèle se concentre à la frontière F-G (5 500–6 200 K). Ces étoiles partagent des largeurs de raies de Balmer et de Ca II similaires, et la distinction repose sur des descripteurs fins (asymétrie du continuum, indices Lick Mg b, Hβ). Cette ambiguïté est visible dans l'espace UMAP : les prédictions erronées F/G se concentrent dans la zone de transition entre les deux populations — ce n'est pas une erreur du classifieur, mais le reflet d'une continuité physique réelle dans la séquence spectrale.
Référence figure : umap_xgboost_FG_confusion.png
Cohérence géographique dans l'espace UMAP
Principe de la validation croisée supervisé/non supervisé
La projection UMAP des prédictions XGBoost permet une validation qualitative du modèle : si le classifieur supervisé a appris la même structure physique que UMAP (non supervisé), les prédictions doivent suivre la géographie de la projection.
Résultats
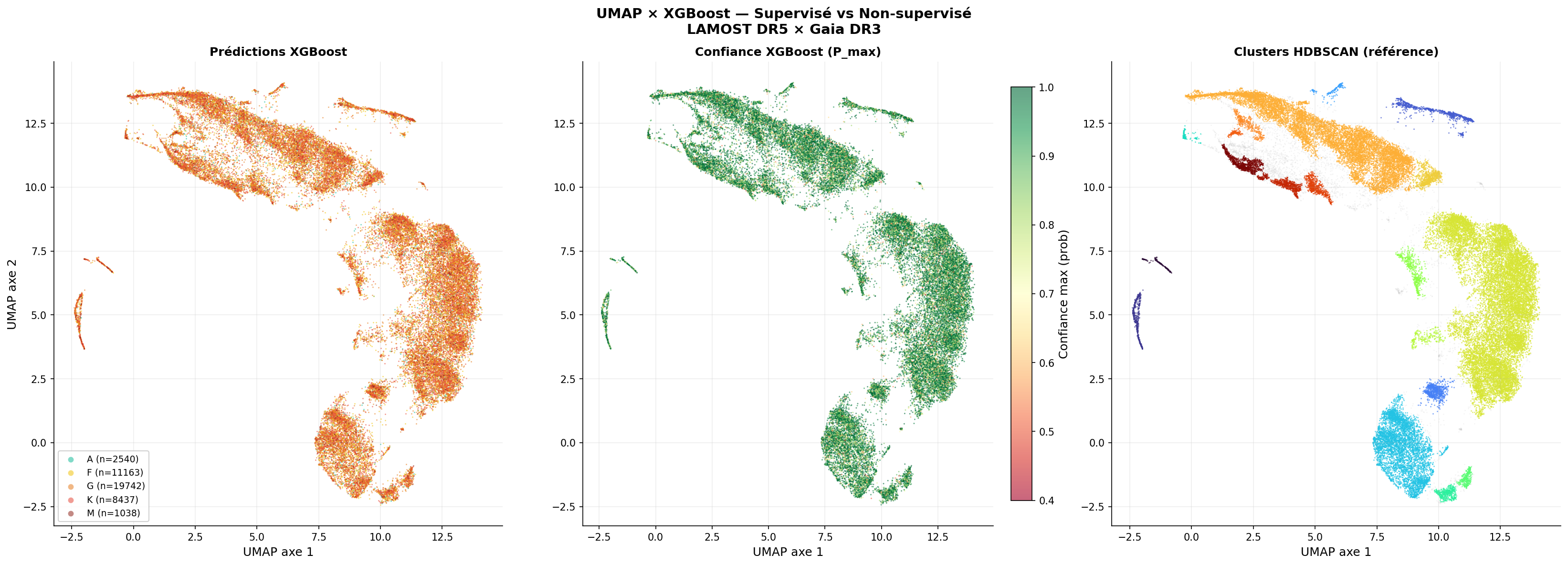
La géographie XGBoost dans UMAP est cohérente avec la structure non supervisée : supervisé et non supervisé capturent la même physique.
Cette correspondance directe entre la structure émergente de UMAP (sans étiquettes) et la classification XGBoost (avec étiquettes) démontre que les deux approches capturent la même structure physique sous-jacente : la séquence de température effective de la classification MK de Harvard.
Interprétabilité SHAP — quelles features décident ?
L'analyse SHAP (SHapley Additive exPlanations) sur le modèle spectro_only=True révèle l'importance réelle des descripteurs dans les décisions du classifieur.
PCA vs XGBoost — deux questions, deux réponses
Ces deux approches semblent contradictoires (PCA trouve la température, XGBoost trouve Ca II/métallicité) mais sont en réalité complémentaires :
Lien avec le pipeline AstroSpectro complet
Ce résultat s'inscrit dans une progression cohérente du projet AstroSpectro :
ra, dec, redshift apportaient un signal corrélé via les biais observationnels de LAMOST (programmes d'observation ciblés par type spectral), pas via la physique réelle. Leur suppression force le modèle à apprendre de vrais indicateurs physiques → meilleure généralisation.Utilisation du modèle
Charger et prédire
from src.pipeline.classifier import SpectralClassifier
# Chargement du modèle de référence
clf = SpectralClassifier.load_model(
"data/models/spectral_classifier_xgboost_20260213T225019Z.pkl"
)
# Prédire sur de nouveaux spectres (même format de features)
predictions = clf.model_pipeline.predict(X_new)
probabilities = clf.model_pipeline.predict_proba(X_new)
Métadonnées du run de référence
Le run de référence est documenté dans :
data/reports/20260213T225019Z/
├── spectral_classifier_xgboost_20260213T225019Z_meta.json
└── spectral_classifier_xgboost_20260213T225019Z.pkl
Le meta JSON contient les hyperparamètres finaux, la liste des 59 features sélectionnées, les labels de classes, et le fichier source d'entraînement (features_20251217T160120Z.csv).