Premier Lancement : De A à Z
Maintenant que votre environnement est configuré, nous allons lancer le pipeline complet via le notebook principal 00_master_pipeline.ipynb.
Ce notebook orchestre toutes les étapes, de la sélection des données à la génération d’un rapport de session.
Si vous utilisez un Codespace, l’environnement est déjà prêt.
Ouvrez notebooks/ et lancez 00_master_pipeline.ipynb.
Un petit jeu de données de démonstration peut déjà être présent selon la configuration du Codespace.
- Vous exécutez bien dans le kernel AstroSpectro (Py3.11) (ou équivalent).
- Votre fichier
.envest configuré si vous utilisez des accès (voir Connexion Gaia). - En local :
data/raw/contient des spectres (sinon faites l’étape 1).
Étape 1 : Acquérir des Données (si nécessaire)
Si c’est votre toute première exécution en local, le dossier data/raw/ est vide :
- Ouvrez le notebook
notebooks/01_download_spectra.ipynb. - Utilisez l'interface ci-dessous pour lancer le téléchargement. Pour un test rapide, sélectionnez environ 1000 spectres.
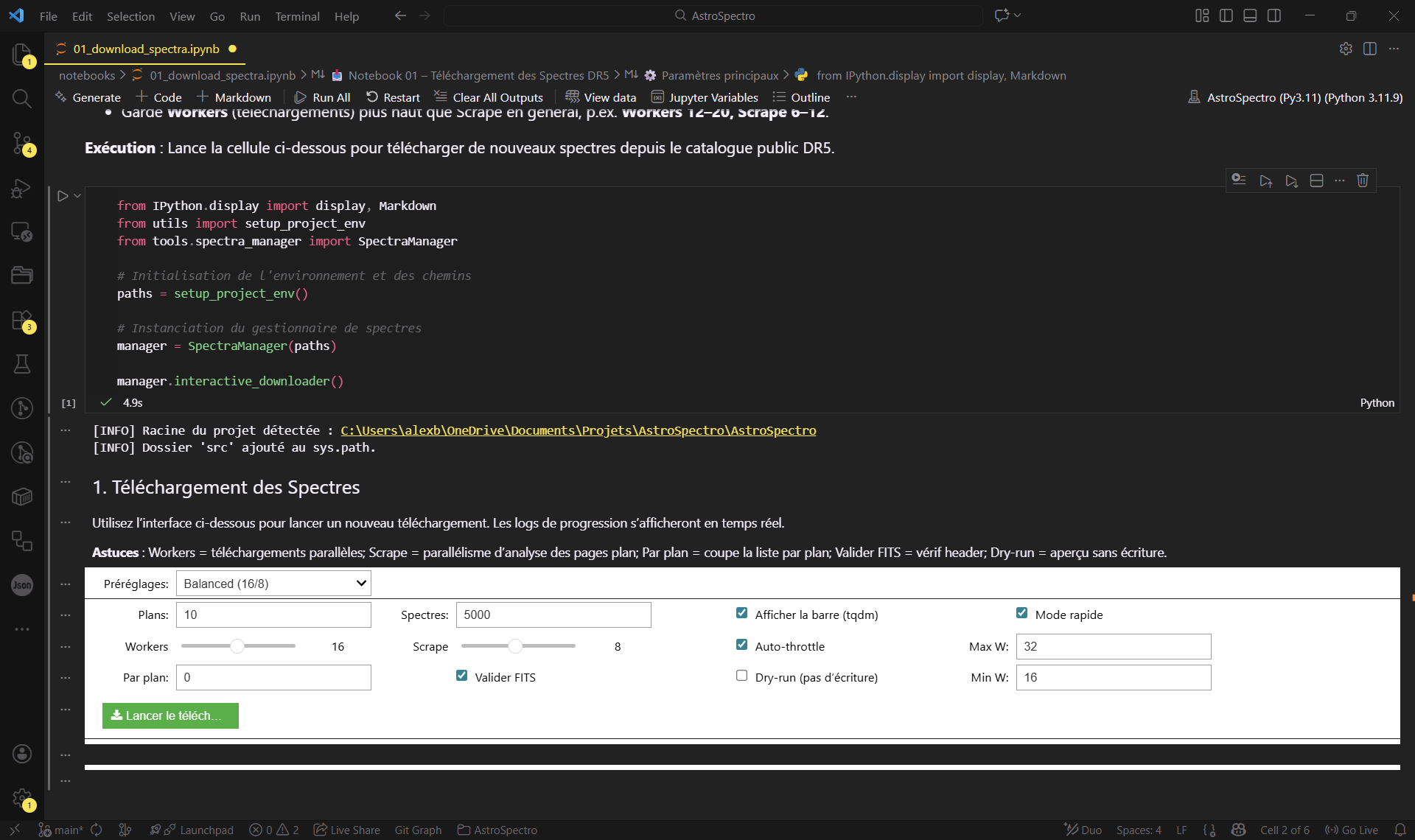
Figure 1 : L'interface interactive pour configurer et lancer l'acquisition des données.
Besoin des options avancées (workers/scrapes/tqdm/auto-throttle/validation FITS/dry-run) ? Elles sont documentées dans Guides d’utilisation → Téléchargement.
Étape 2 : Lancer la pipeline complète
Une fois que vous avez des données :
- Ouvrez le notebook principal :
notebooks/00_master_pipeline.ipynb. - Exécutez toutes les cellules de haut en bas.
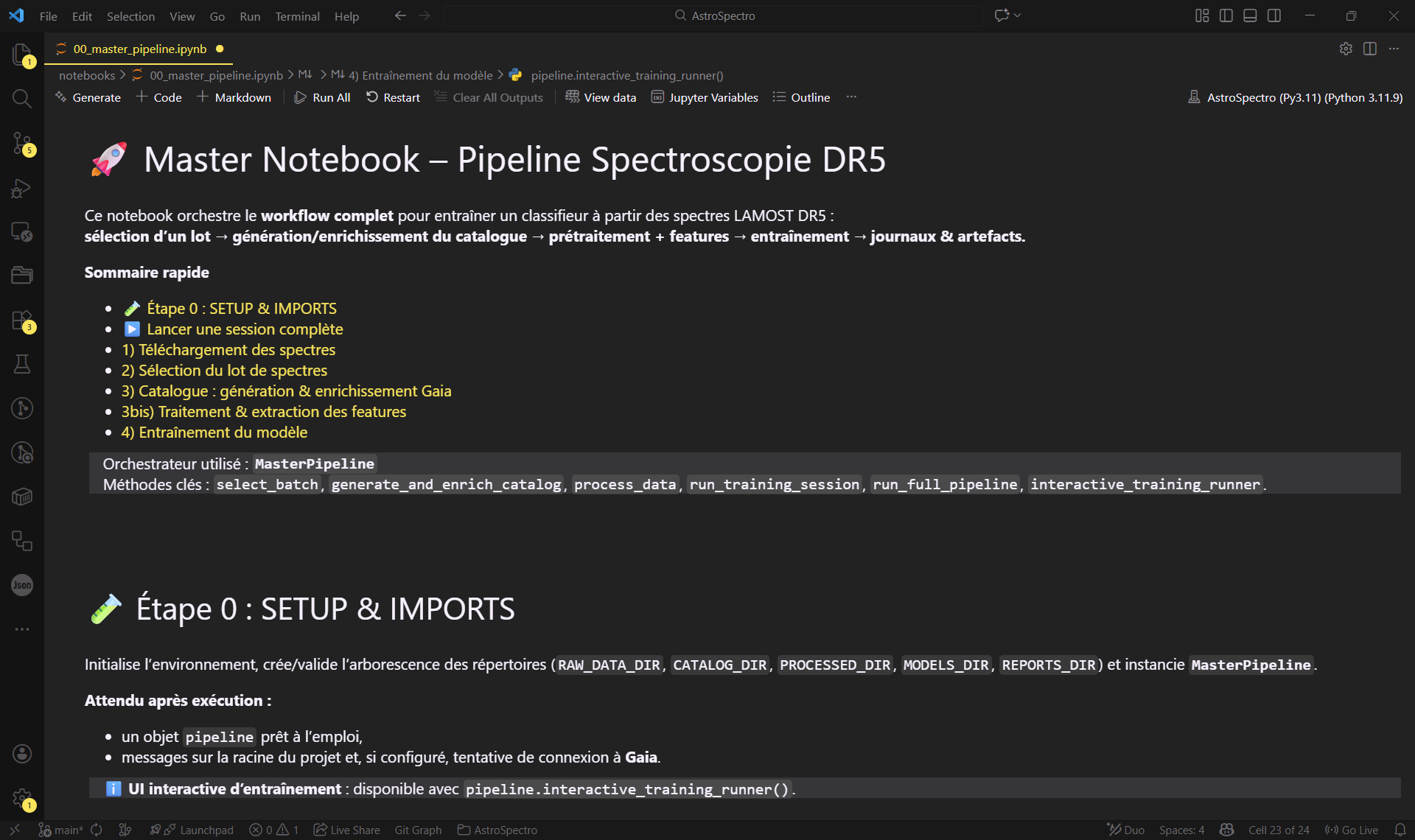
Figure 2 : L'orchestrateur principal (00_master_pipeline) prêt à l'emploi.
Le notebook exécute séquentiellement le MasterPipeline :
- Initialise l'environnement, l'accès à Gaia, ainsi que crée ou valide l'arborescence des répertoires nécessaires. (la première connection peut prendre quelques temps)
- Sélection d’un lot : Définissez simplement le nombre de spectres souhaité (ex:
batch_size=1000) et conservez la stratégie par défaut (random). - Génération d’un catalogue local pour ce lot.
- Traitement & Extraction des features (plusieurs dizaines de features possibles selon la config).
- Entraînement & Évaluation via une interface interactive.
Entraînement (premier run recommandé)
Dans l’interface d’entraînement, vous pouvez choisir plusieurs modèles (ex. XGBoost, RandomForest, SVM, ExtraTrees, KNN, MLP, etc.) et ajuster des hyperparamètres.
Objectif : valider que la chaîne complète fonctionne (pas optimiser la performance).
Pour une première exécution, privilégiez la simplicité :
- Pour un premier run, on recommande XGBoost ou RandomForest (rapides, robustes), puis explorer les autres modèles ensuite.
- Laissez les valeurs par défaut (ou un template/preset si disponible)
- Lancez le batch / l’exécution
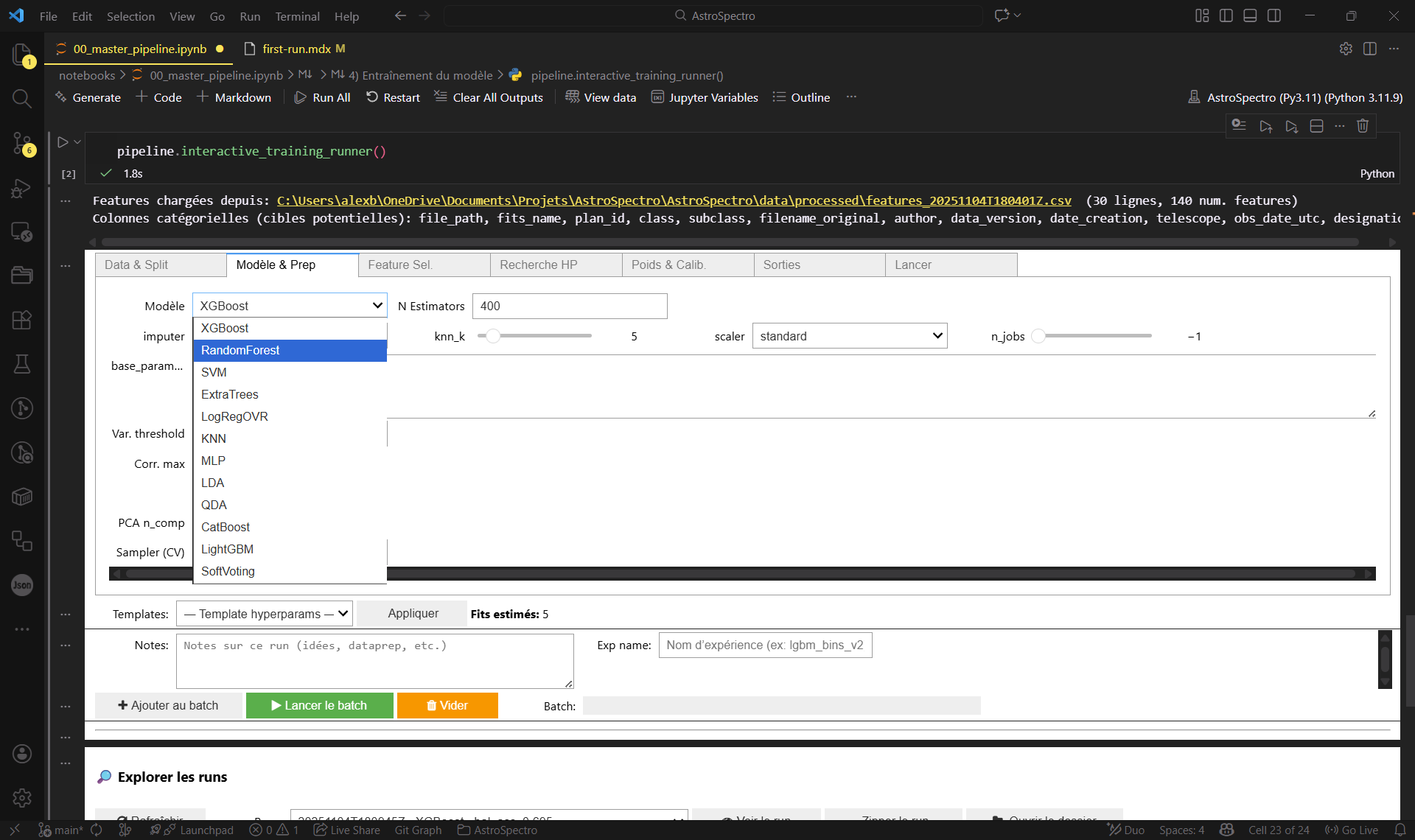
Figure 3 : Le panneau de contrôle pour choisir votre modèle (XGBoost/RF) sans toucher au code.
Toute la documentation “propre” sur : templates/préréglages, recherche HP, calibration, choix du modèle, etc. est dans Guides d’utilisation → Entraînement.
Étape 3 : Examiner les Résultats
À la fin de l’exécution, plusieurs artefacts sont produits :
- Un fichier CSV dans
data/processed/(features prêtes pour analyse). - Un modèle
.pkldansdata/models/. - Un rapport de session JSON dans
data/reports/, ainsi que les graphiques d'analyse des résultats (feature_importance,roc,confusion_matrix,precision_recal, etc).
Félicitations !
Vous avez exécuté le pipeline de bout en bout et obtenu vos premières classifications.
Vous êtes maintenant prêt à explorer le projet plus en profondeur !
Et maintenant ? Choisissez votre voie :
Comprendre la Science
Découvrez les concepts astrophysiques derrière le code : classification spectrale, normalisation des flux et équations.
Devenir un Expert
Apprenez à configurer les workers, optimiser le téléchargement et créer vos propres presets d'entraînement.