Cette page présente les résultats obtenus par le pipeline AstroSpectro sur N = 43 019 spectres LAMOST DR5 × Gaia DR3 décrits par p = 183 descripteurs spectroscopiques. Les résultats couvrent deux axes complémentaires : l'analyse non supervisée par réduction de dimension (PCA, UMAP, t-SNE, HDBSCAN) et la classification supervisée (XGBoost avec validation SHAP).
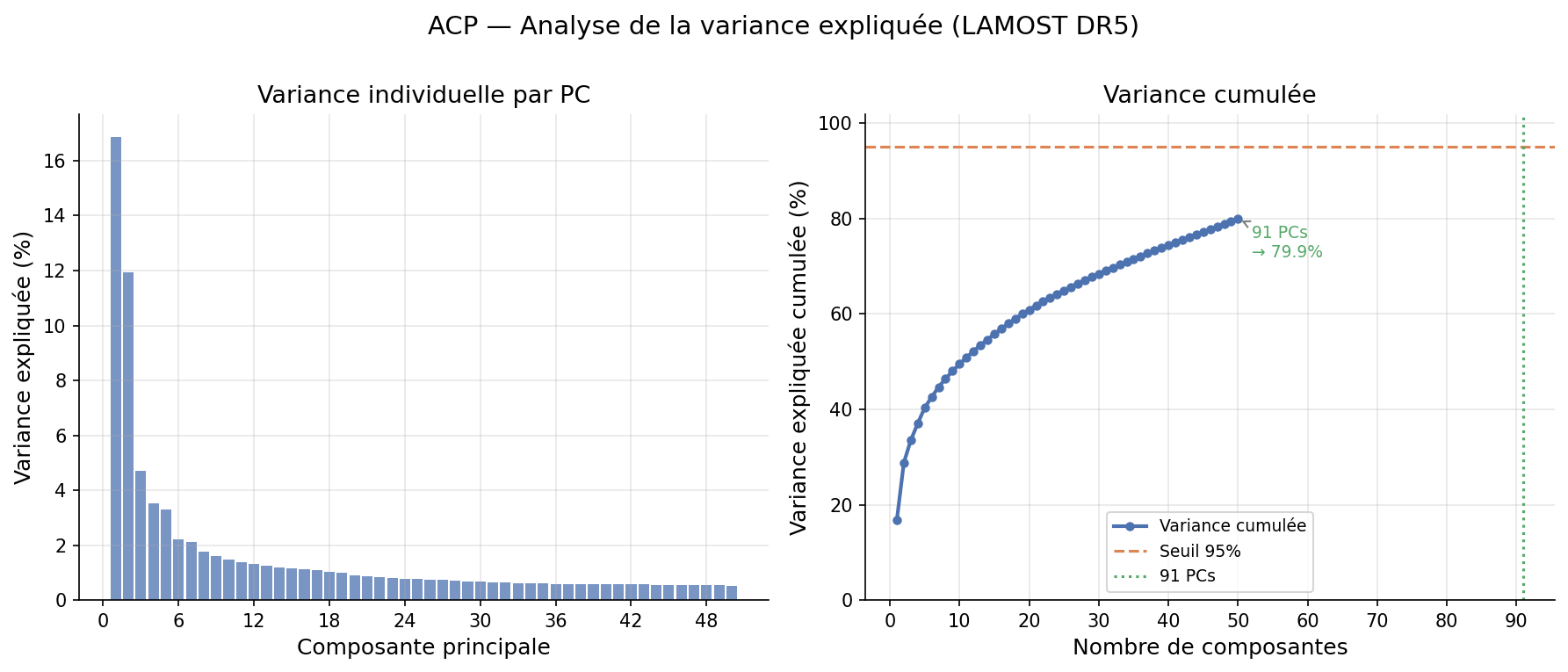
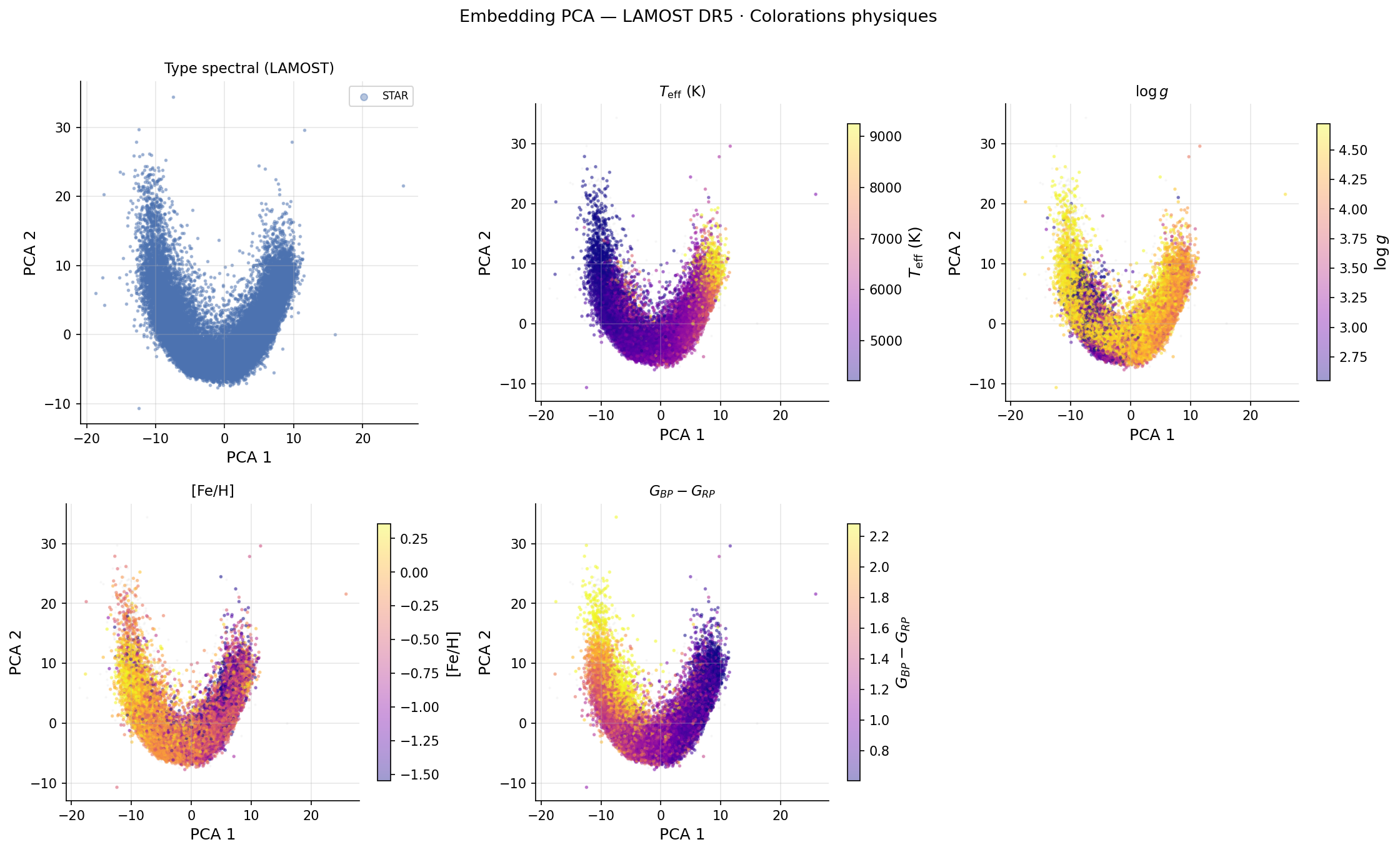
La PCA sur les 183 descripteurs standardisés révèle une haute dimensionnalité intrinsèque : il faut 91 composantes pour capturer 95 % de la variance, sans coude net dans le spectre des valeurs propres.
Seuil V(K)
Composantes K
Interprétation
28,8 %
2
PC1 + PC2 uniquement — visualisation
80 %
51
Analyse rapide
95 %
91
Seuil retenu pour UMAP/t-SNE
99 %
100
Quasi-totalité de la variance
K =
2
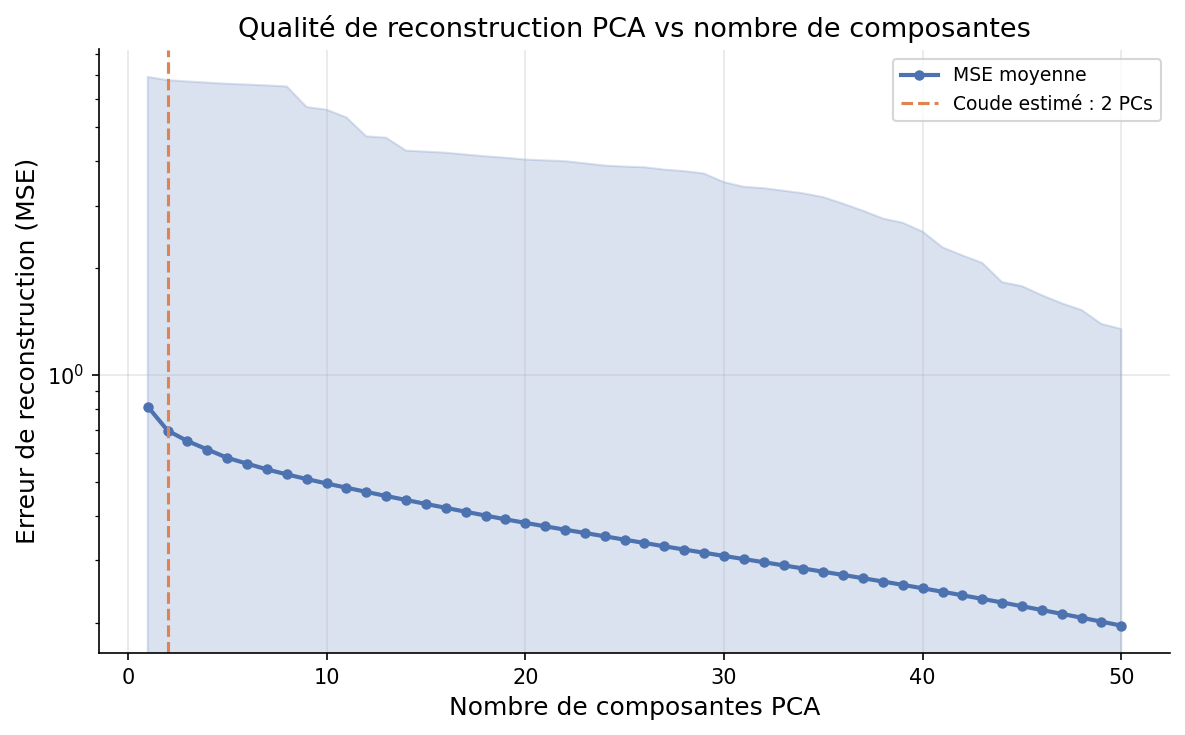
Variance : 28.8%MSE: 0,696
PC1 + PC2 uniquement — visualisation basique 2D.
K =
10
Variance : 50.6%MSE: 0,494
Capture de la moitié de l'information physique.
K =
51
Variance : 80%MSE: 0,196
Seuil d'analyse rapide — bon compromis vitesse/précision.
K =
91
Variance : 95%MSE: ~0,050
SEUIL RETENU POUR UMAP/t-SNE — Capture l'essentiel de la variance.
K =
100
Variance : 99%MSE: <0,010
Quasi-totalité de la variance (inclut le bruit résiduel).
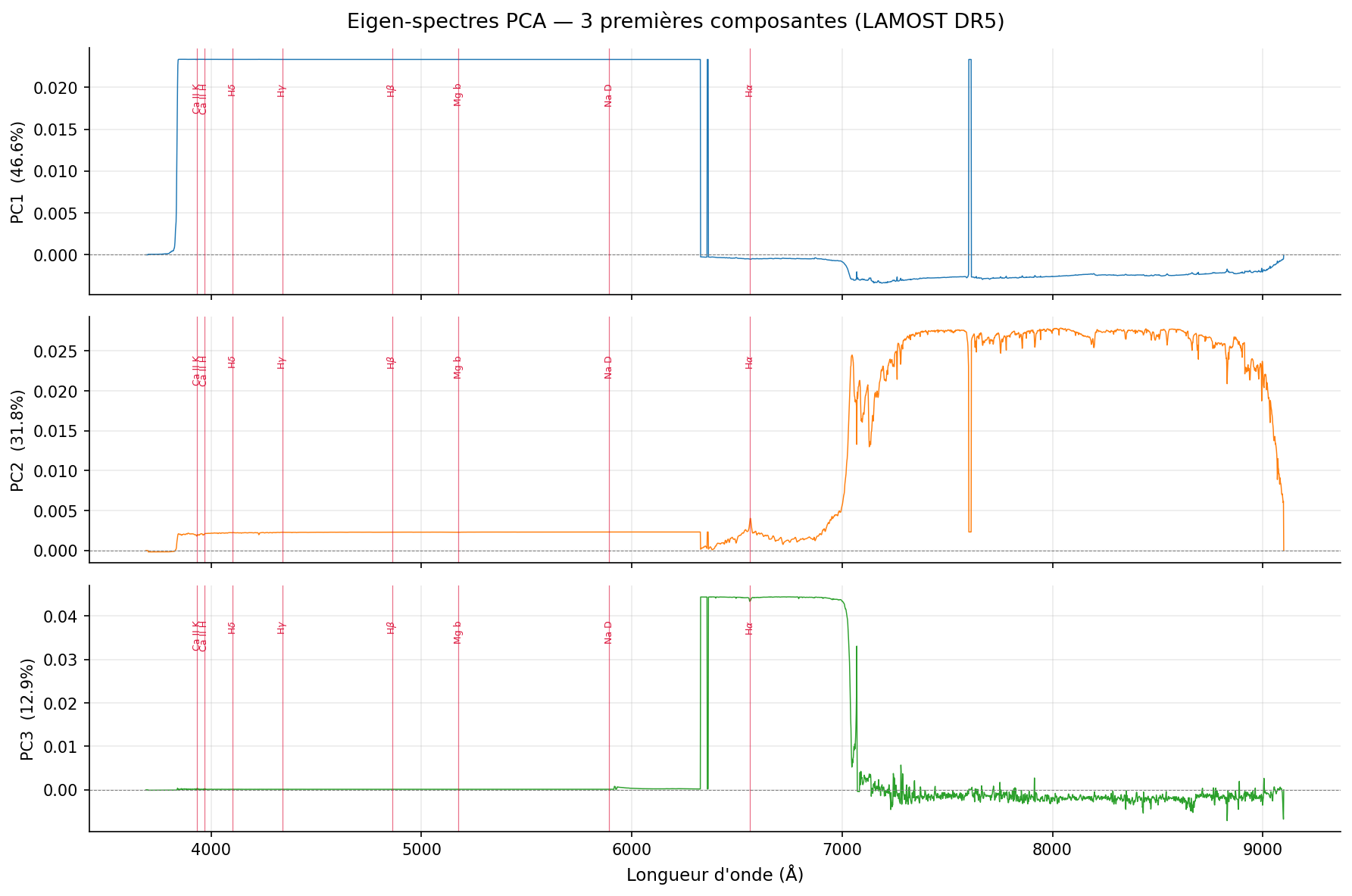
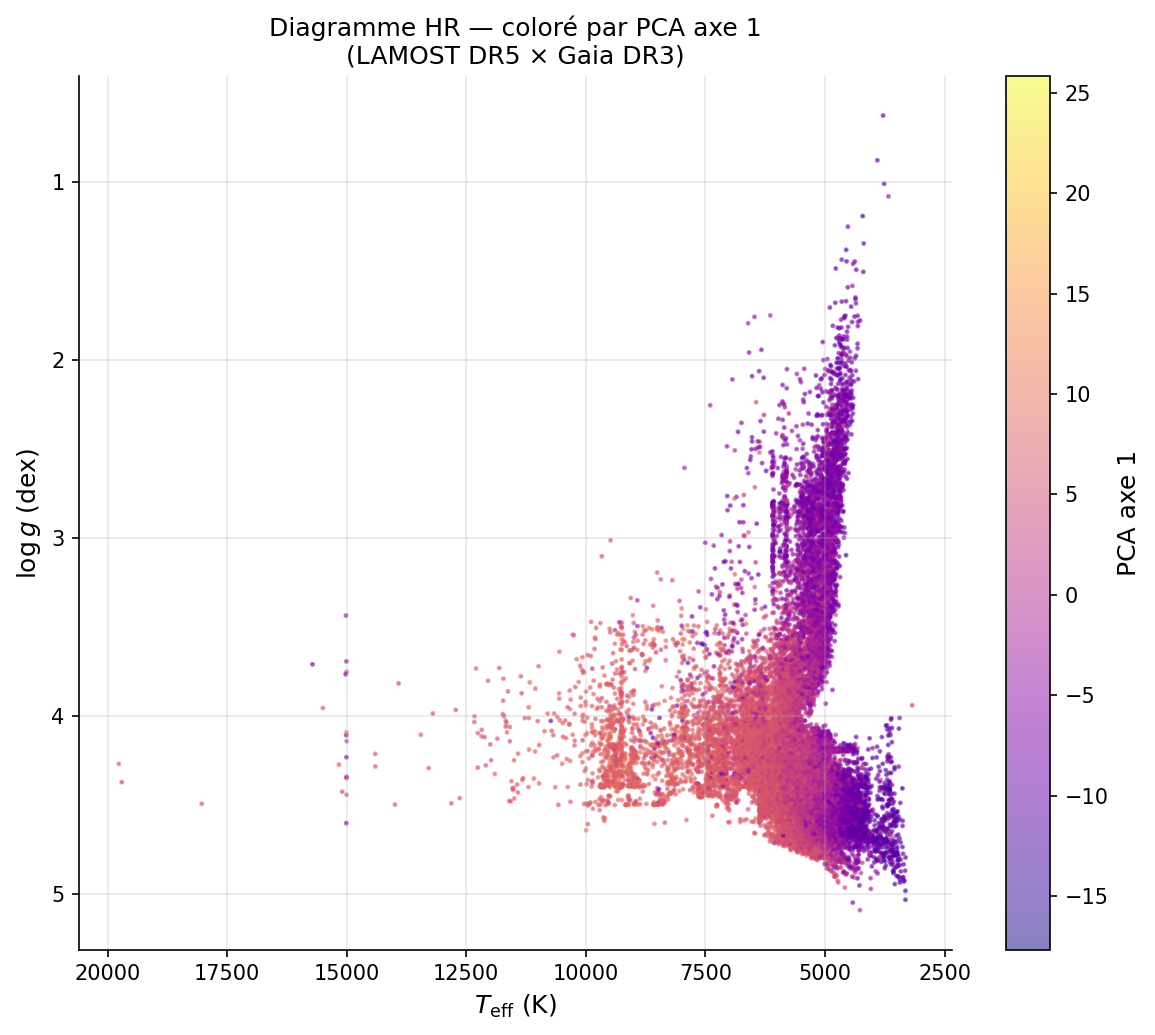
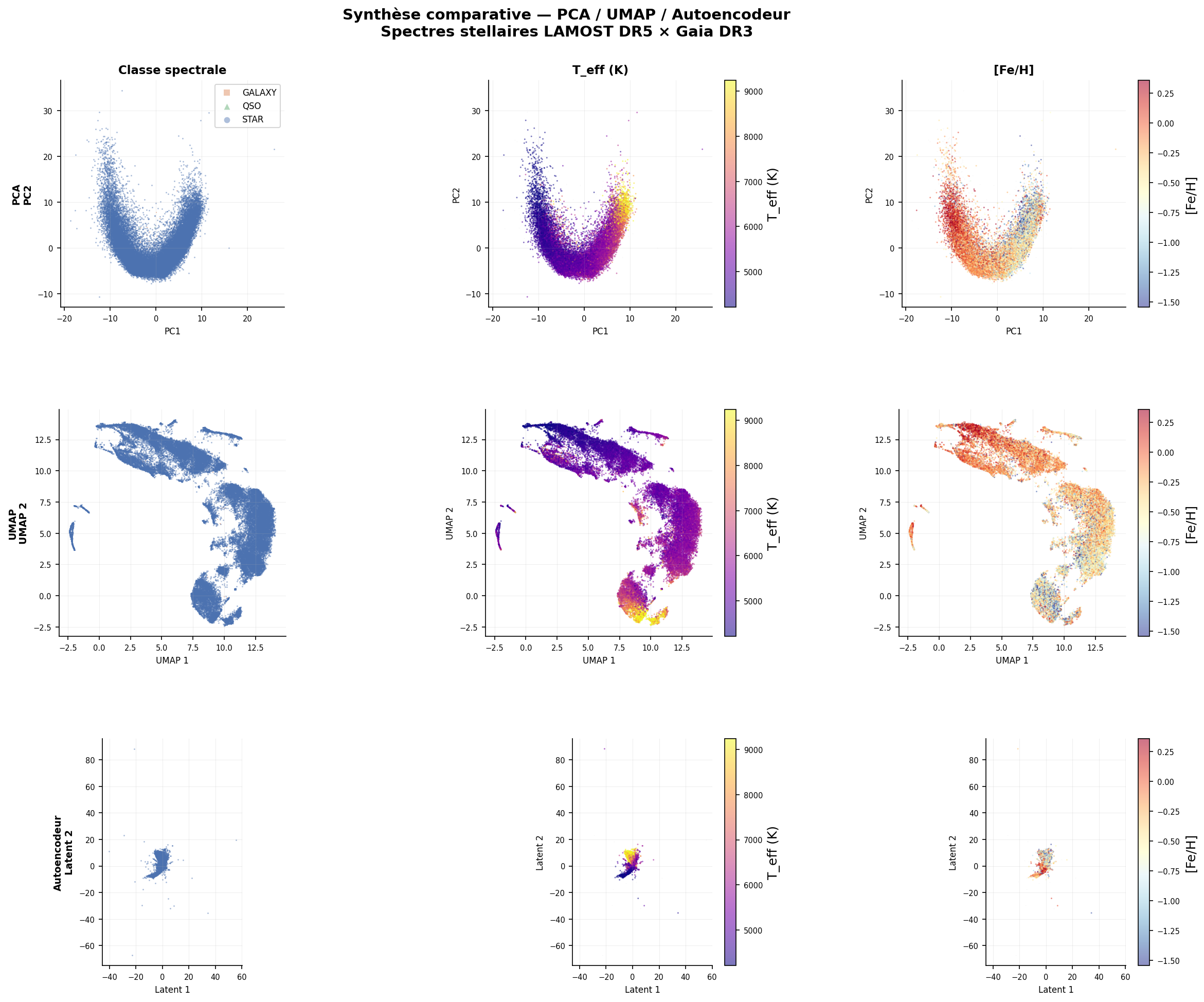
PC1 (16,9 %, λ₁ = 30,19) — Axe thermique : ρ(PC1, Teff) = +0,831. Dominé par les raies de Balmer (31,5 %) et le calcium ionisé (22,4 %). Les étoiles chaudes (A-F, > 7 000 K) occupent le côté positif ; les étoiles froides (K-M, < 5 000 K) le côté négatif.
PC2 (12,0 %, λ₂ = 21,39) — Axe métallicité (partiellement contaminé) : Dominé par le fer et les métaux (43,3 %). La corrélation ρ(PC2, SNRr) = −0,310 révèle une contamination instrumentale — PC2 n'est pas un axe de métallicité pur.
K composantes
MSE(K)
Variance capturée
2
0,696
30,4 %
10
0,494
50,6 %
50
0,196
80,4 %
91
~0,050
95,0 %
Eigenspectra sur flux bruts (10 000 spectres, 3 921 canaux) : Trois composantes suffisent à expliquer 91,3 % de la variance des flux bruts (vs 91 composantes pour les 183 descripteurs). PC1_flux = pente de couleur (Teff) · PC2_flux = montée infrarouge étoiles froides · PC3_flux = coupure instrumentale bleue/rouge.
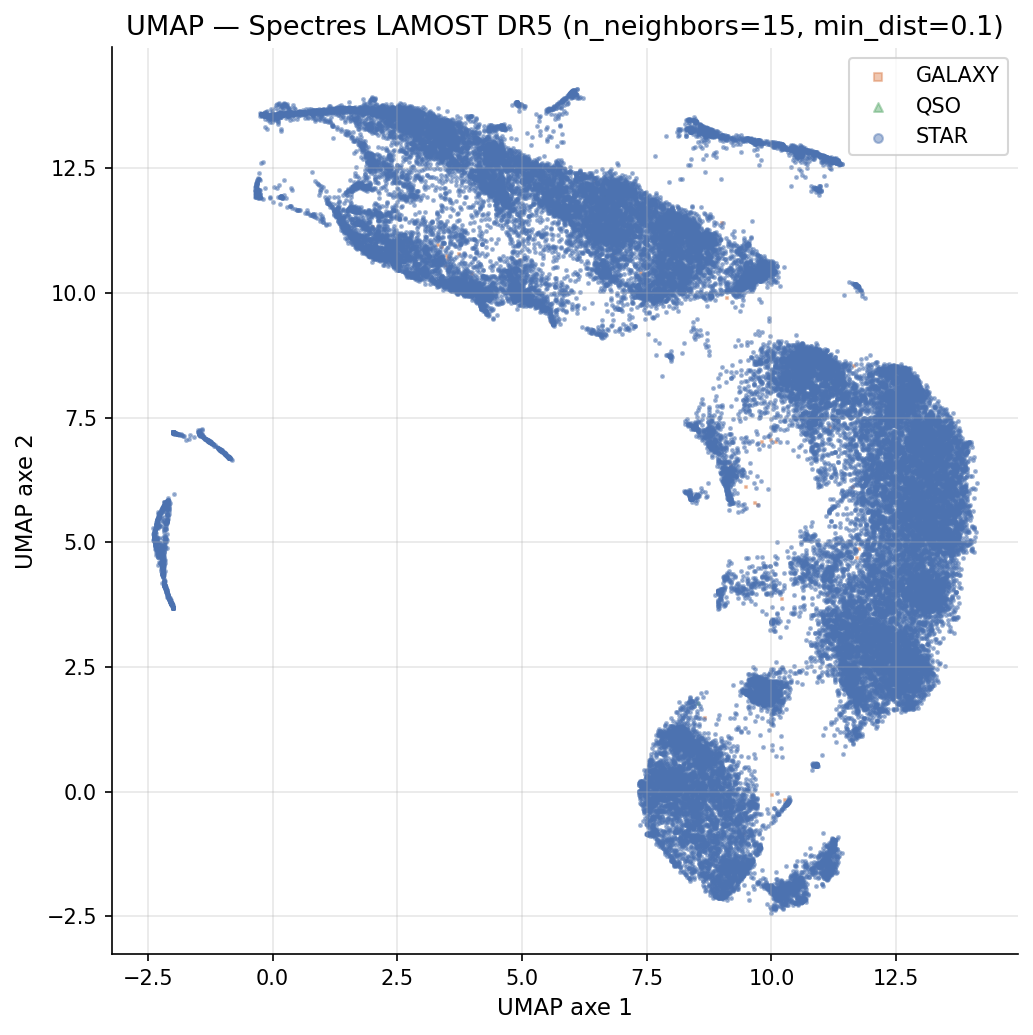
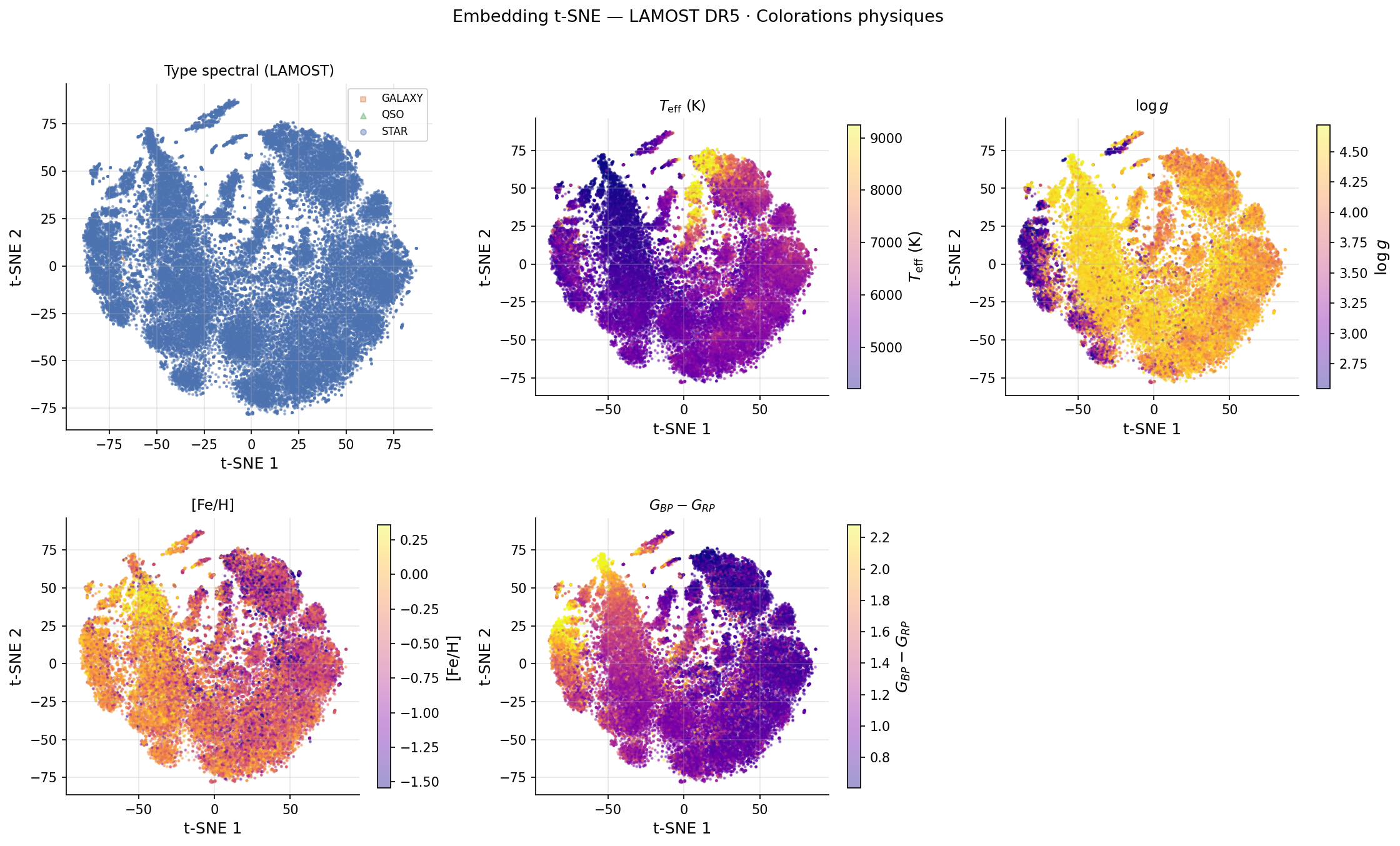
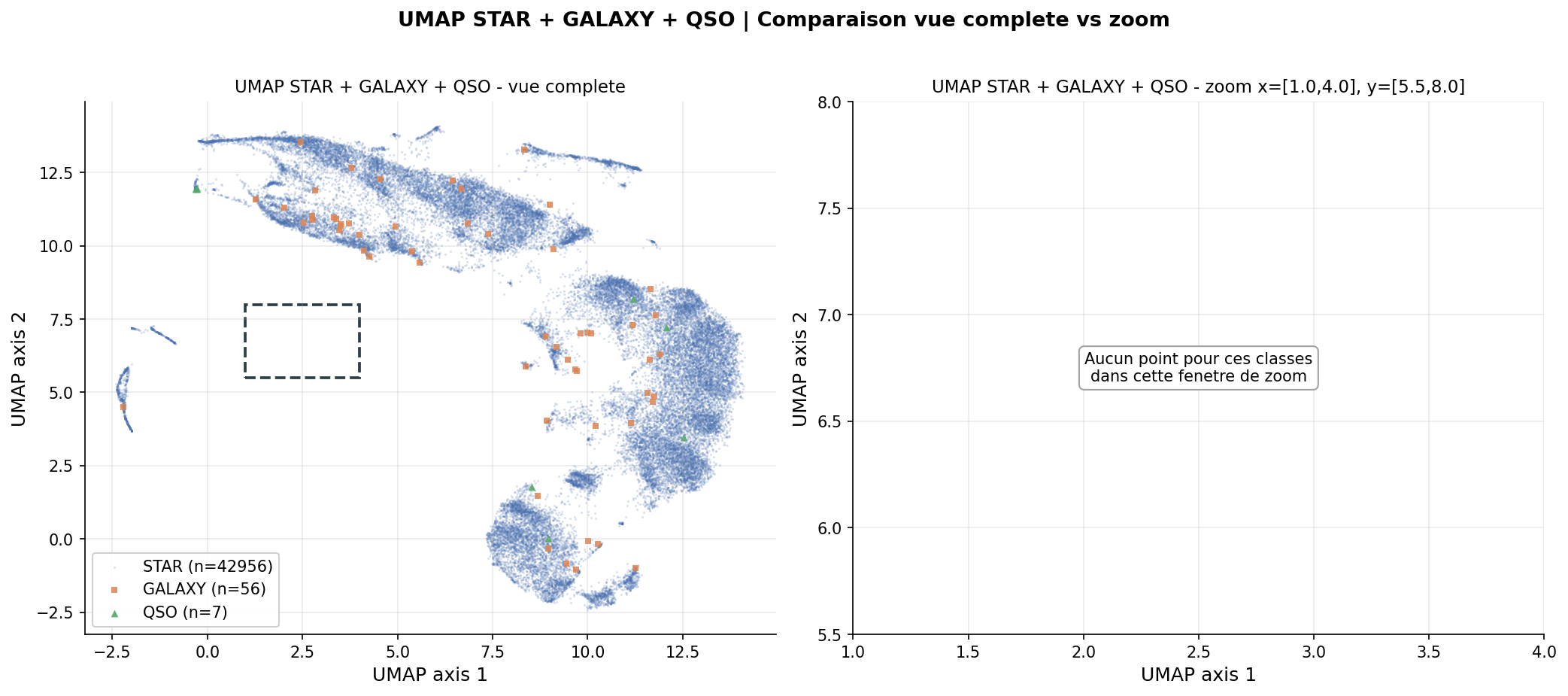
UMAP est appliqué aux 91 composantes PCA avec n_neighbors=15, min_dist=0.1, 200 époques (t = 40,1 s, Ryzen 9 5950X). La projection révèle une structure en «continent continu» où la séquence de Harvard (M-K-G-F-A) se déploie sans supervision.
Corrélations : ρ(UMAP axe 1, Teff) = +0,464. La classe de luminosité (naines vs géantes) induit une bifurcation topologique visible dans la coloration par log g.
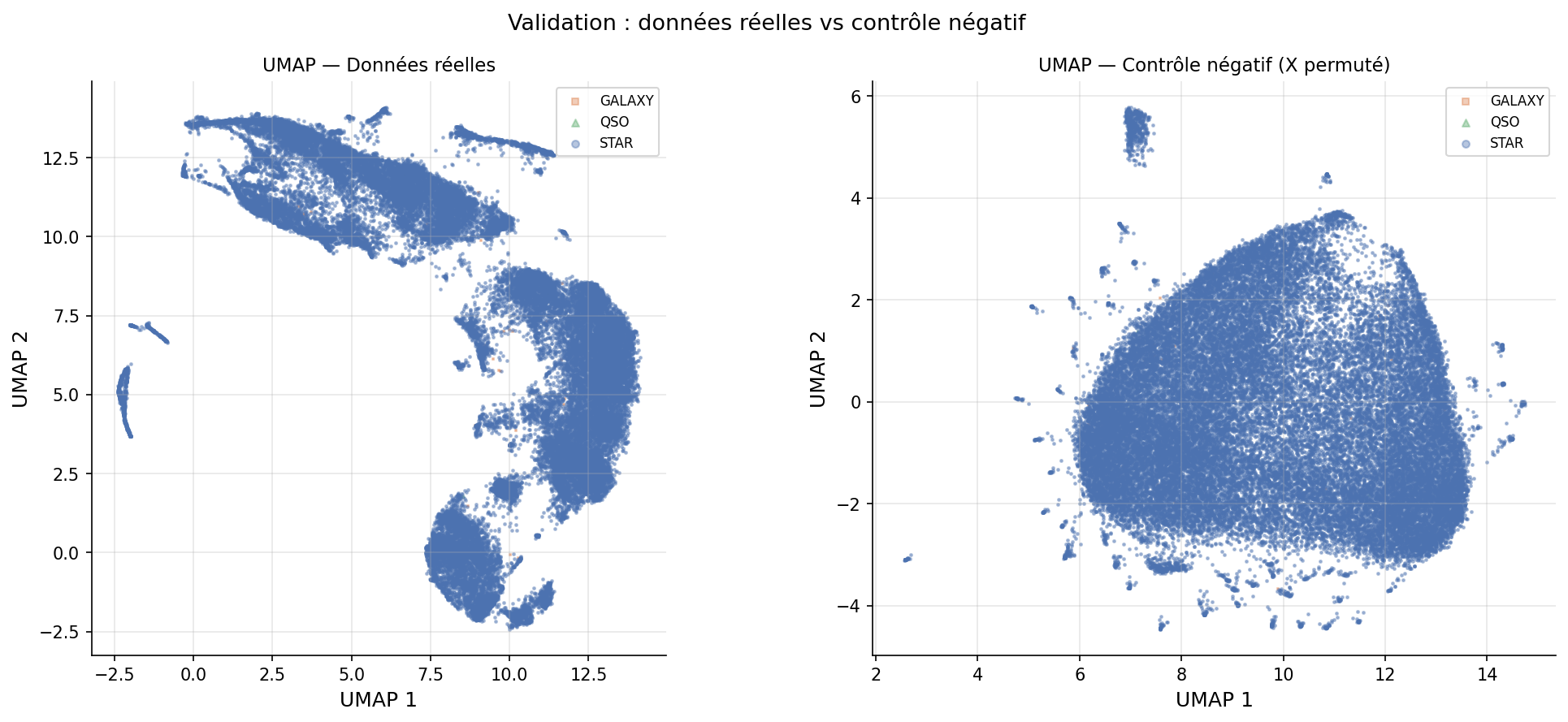
Contrôle négatif : UMAP appliqué aux données avec colonnes permutées aléatoirement → nuage compact homogène sans structure. La structure observée est d'origine physique, non un artefact algorithmique.
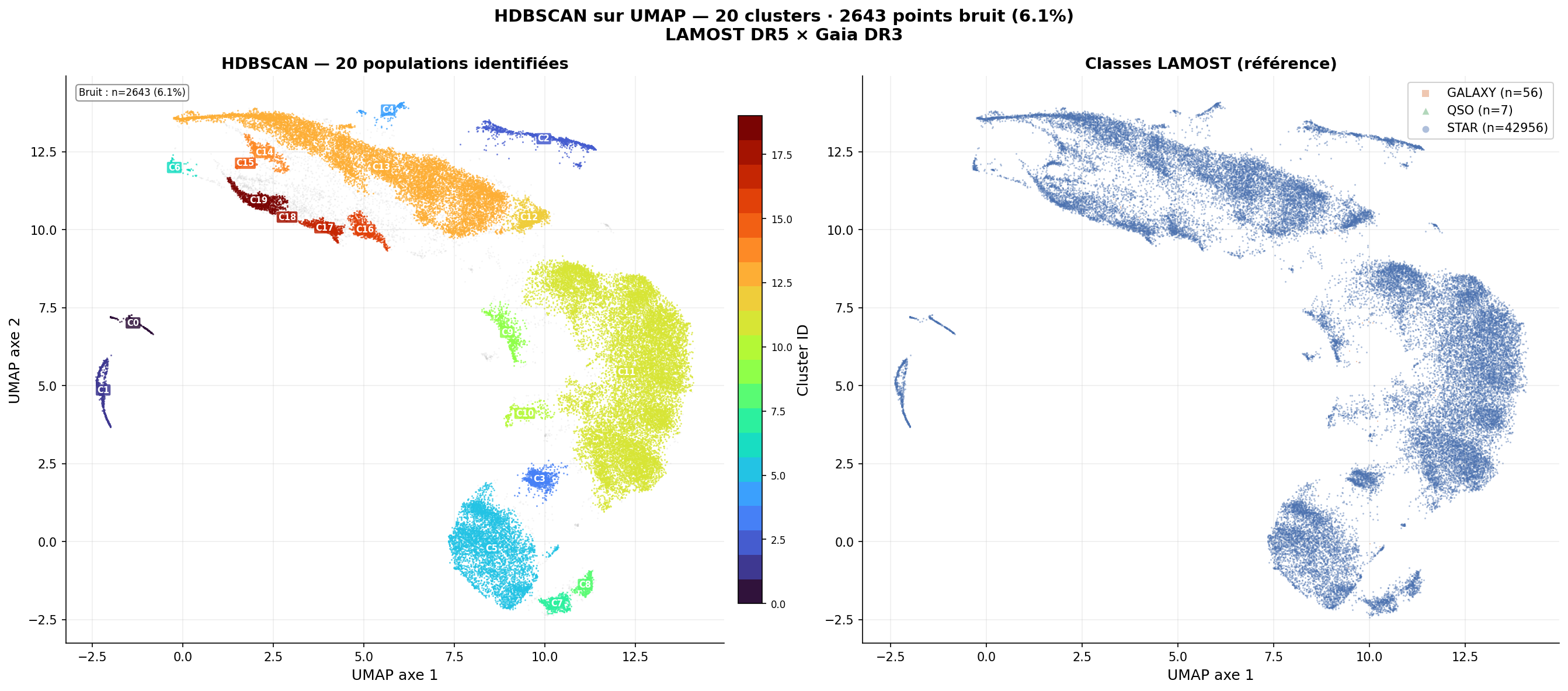
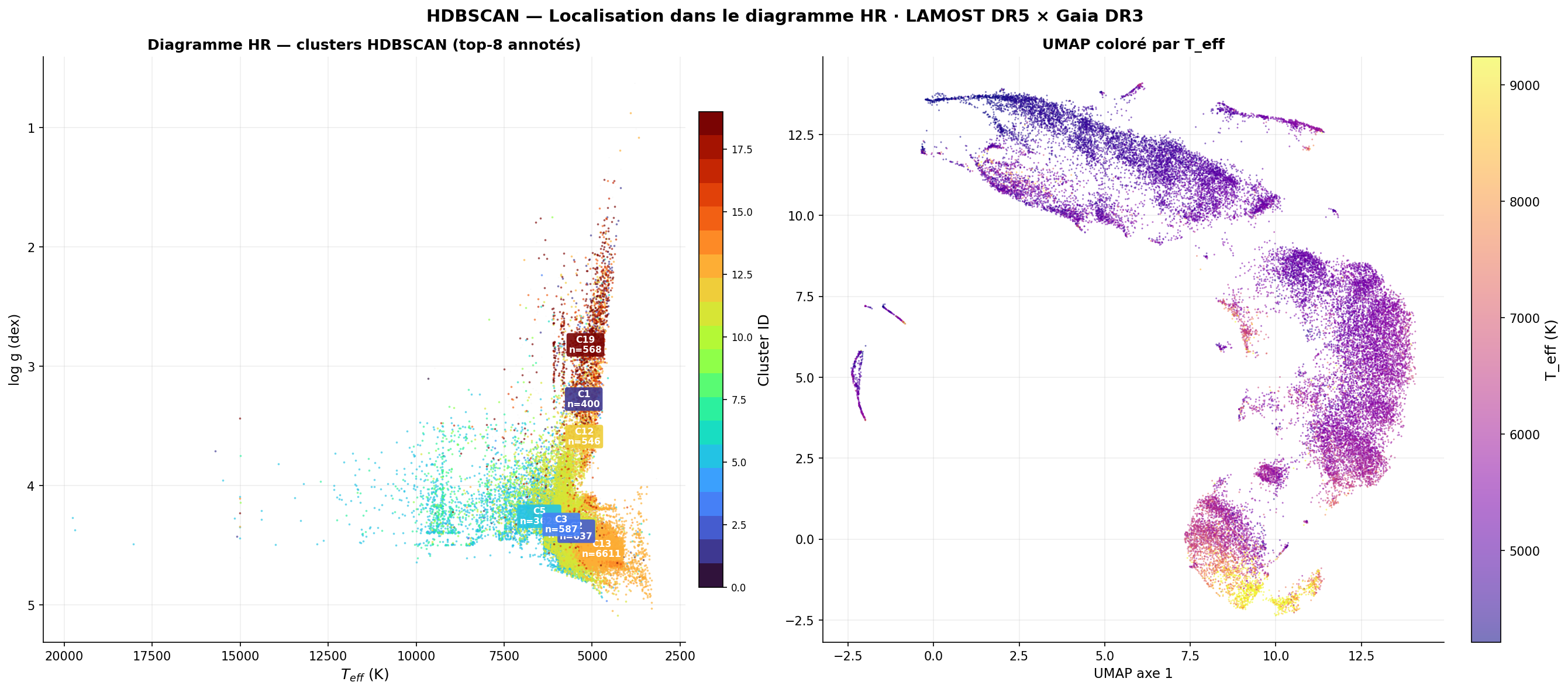
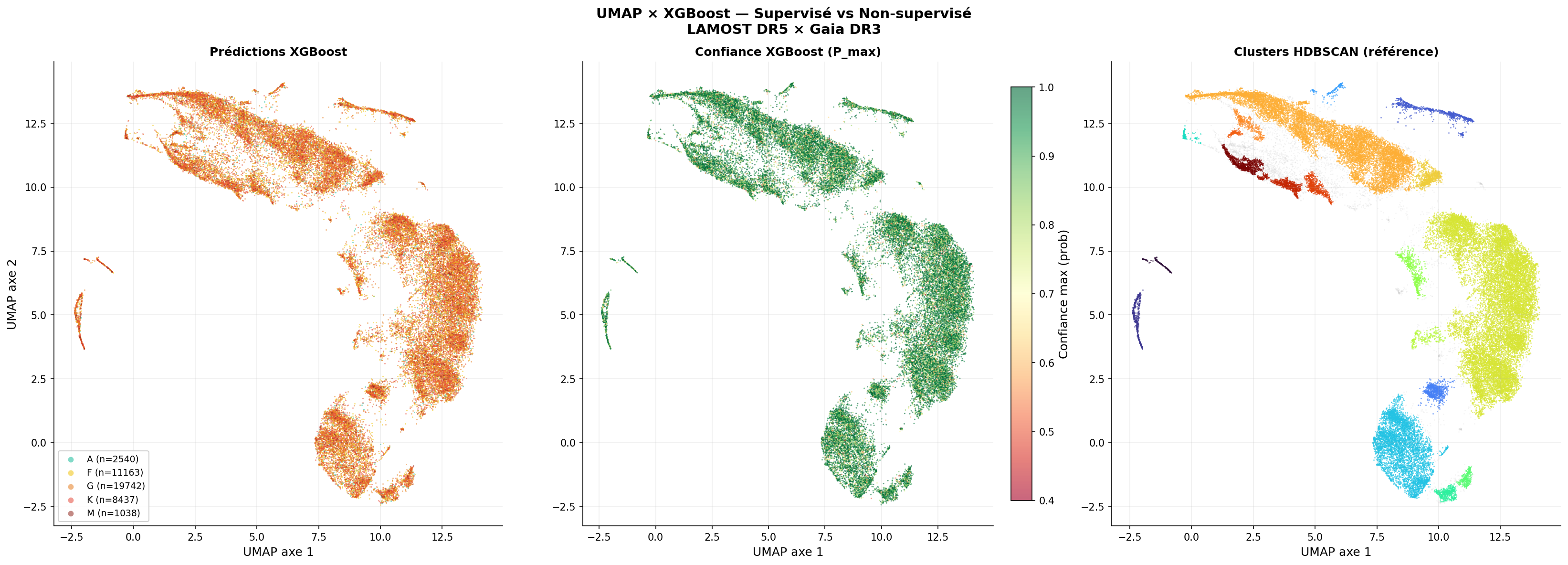
Clusters HDBSCAN — 20 groupes sans aucune étiquette
20
Clusters
2 643
Bruit (6,14 %)
16 716
Cluster C11 (étoiles)
10 373
Cluster C13 (étoiles)
Top 12 clusters — population (étoiles)
C11
16 716
Séquence principale G-K
C13
10 373
Naines K froides
C5
5 083
C3
818
C2
915
C19
900
Sous-géantes / base RGB
C12
851
Sous-géantes / base RGB
C1
654
Sous-géantes / base RGB
C16
620
C17
615
C9
576
C7
474
min_cluster_size=75 · min_samples=20 · bruit exclus de ce graphe
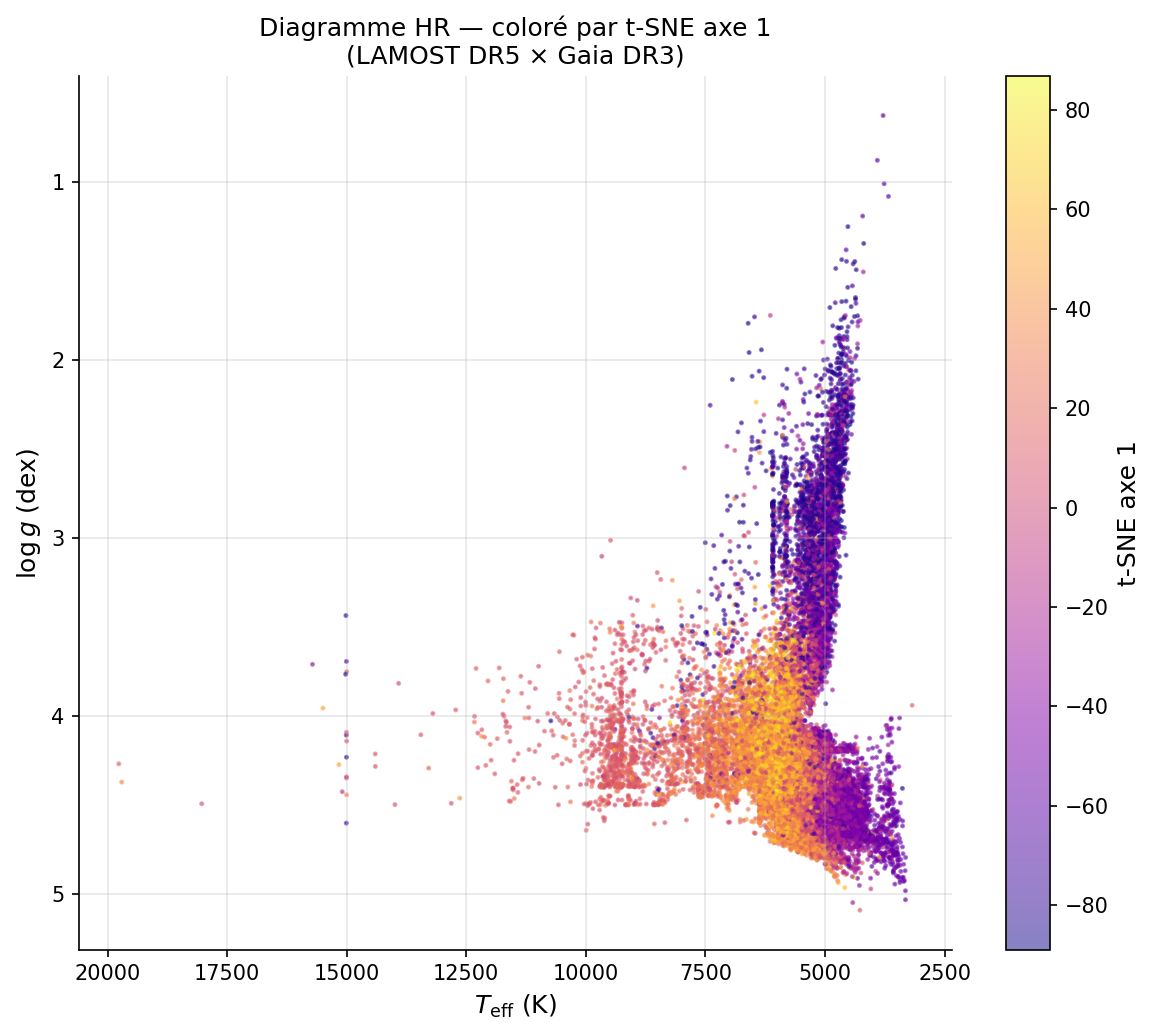
Localisation sur le diagramme HR (Teff × log g × Gaia DR3)
C19, C1, C12
Sous-géantes / base RGB
Ca II renforcé · Balmer affaibli → pression de radiation plus basse
Teff
5000–5500 K
log g
≈ 3,0–3,5
C13
Naines K froides
Cluster le plus peuplé avec identité physique claire
Teff
4500–5000 K
log g
≈ 4,5
C11
Séquence principale G-K
Cluster dominant — population de référence de la séquence principale
Teff
5000–6000 K
log g
≈ 4,0–4,5
Résultat astrophysique original
Sans aucune étiquette ni information sur log g, UMAP organise les spectres de sorte que HDBSCAN récupère la distinction naines/sous-géantes à Teff fixée. Les clusters C19, C1 et C12 se distinguent spectralement par des raies Ca II renforcées et des raies de Balmer affaiblies — signature d'une pression de radiation plus basse à la surface des géantes.
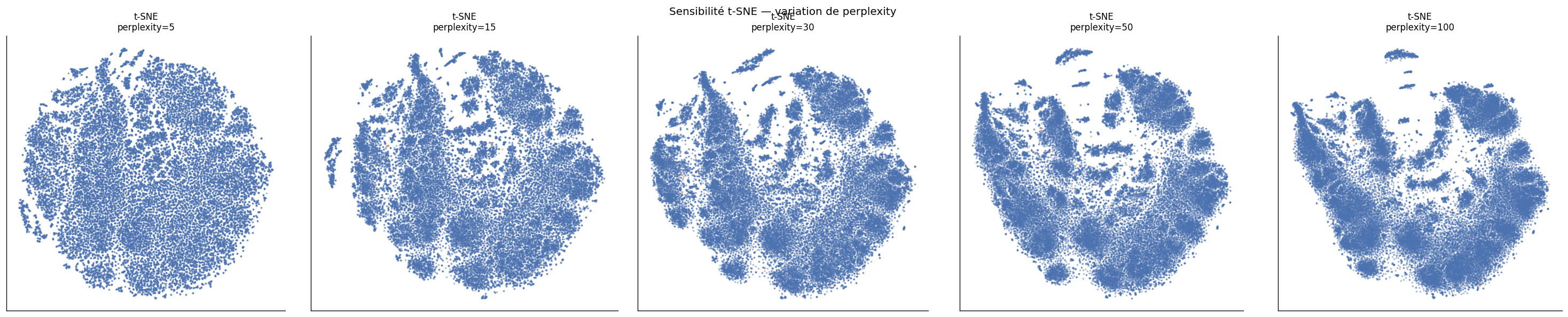
t-SNE est appliqué aux mêmes 91 composantes PCA avec perplexity=30, init='pca', 1 000 itérations (t = 80,2 s, soit 2× UMAP). La projection produit un «archipel» de masses compactes séparées, à l'opposé de la structure continue d'UMAP.
Les étoiles chaudes (A-F, Teff > 7 000 K) forment un amas distinct isolé
La masse centrale regroupe les K-G de la séquence principale
La coloration par log g révèle des clusters de sous-géantes partiellement isolés
t-SNE excelle dans la séparation nette des sous-populations discrètes, tandis qu'UMAP préserve mieux les gradients continus (Teff, [Fe/H]).
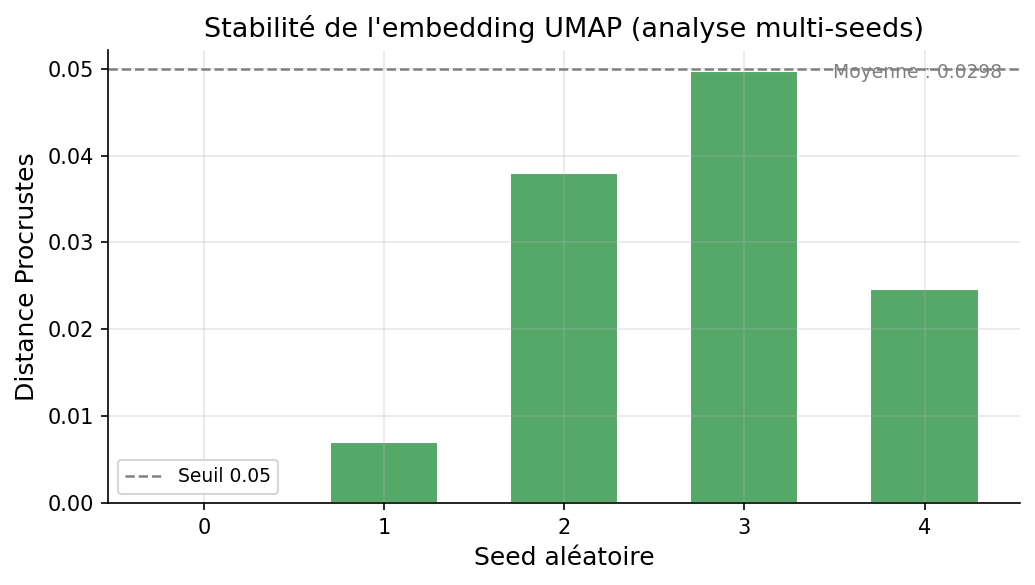
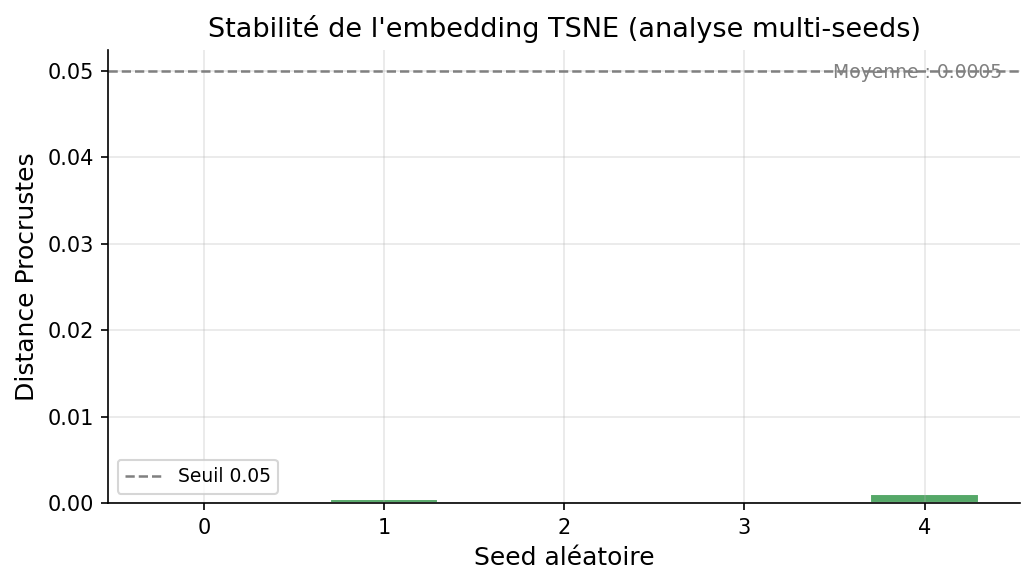
Résultat contre-intuitif — les deux méthodes utilisent la SGD
UMAP
Initialisation spectrale — SGD avec éch. négatif
6e-2
3e-2
0
μ = 3.0e-2
g1
g2
g3
g4
Moyenne dP0.030
t-SNE
init='pca' — pénalité KL concentrée localement
6e-2
3e-2
0
μ = 5.0e-4
g1
g2
g3
g4
Moyenne dP5.0e-4
UMAP instable : L'initialisation spectrale (Laplacien) varie d'une graine à l'autre. La SGD avec échantillonnage négatif introduit une stochasticité forte dans les forces répulsives.
t-SNE stable :init='pca' fixe une position de départ identique. La pénalité KL pénalise uniquement les voisins proches — peu sensible à la graine pour les grandes structures.
Contre-intuitif : passer de 84 % à 87 % en supprimant des features — ra, dec, redshift apportaient un signal corrélé via les biais observationnels de LAMOST (programmes d'observation ciblés par type spectral), pas via la physique réelle. Leur suppression force le modèle à apprendre de vrais indicateurs physiques → meilleure généralisation.
La géographie des prédictions XGBoost dans l'espace UMAP est cohérente avec la structure émergente non supervisée : étoiles A en «péninsule» chaude, G au centre, K en périphérie froide. Les deux approches capturent la même structure physique — la projection UMAP est un espace de validation qualitative pour le classifieur.
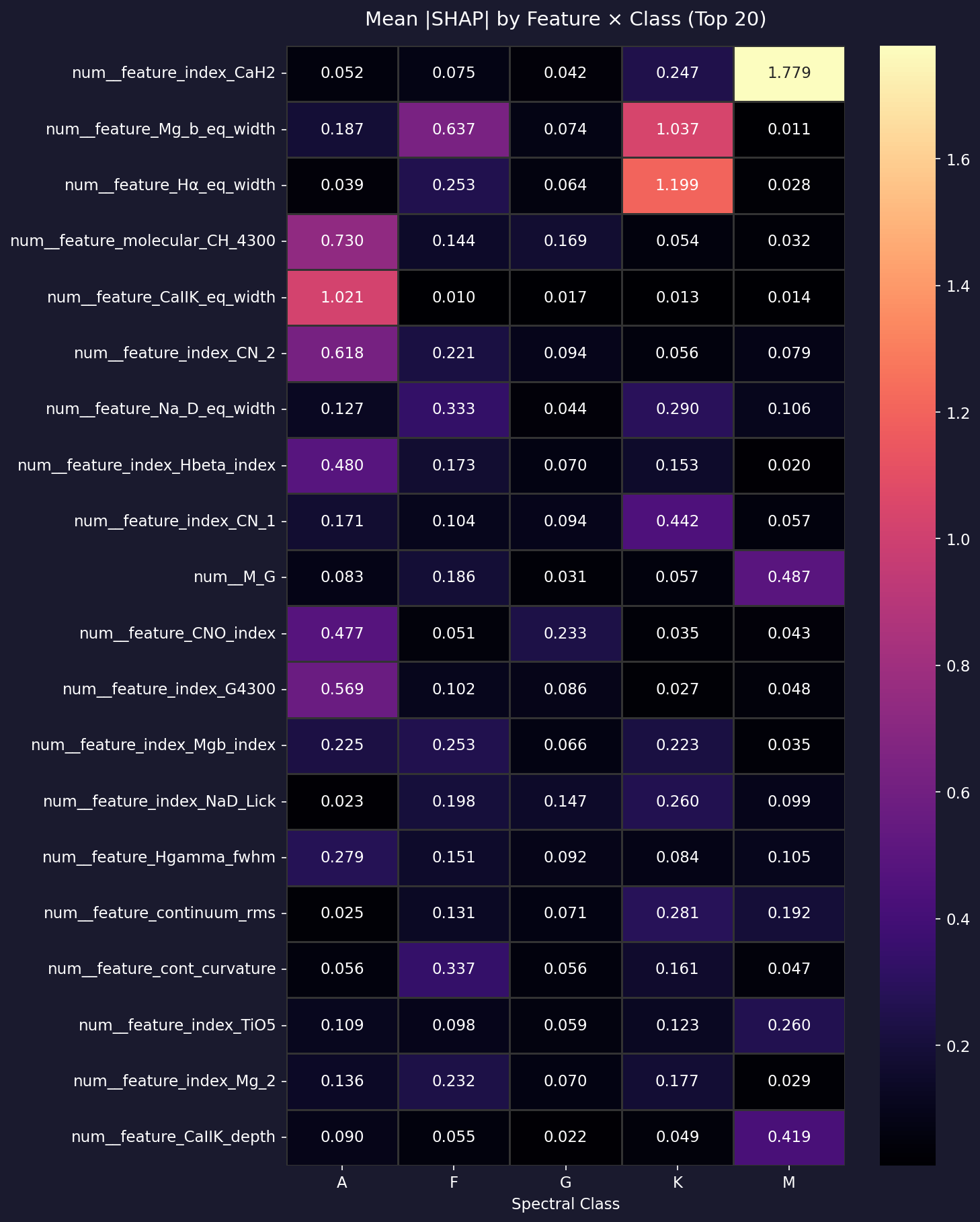
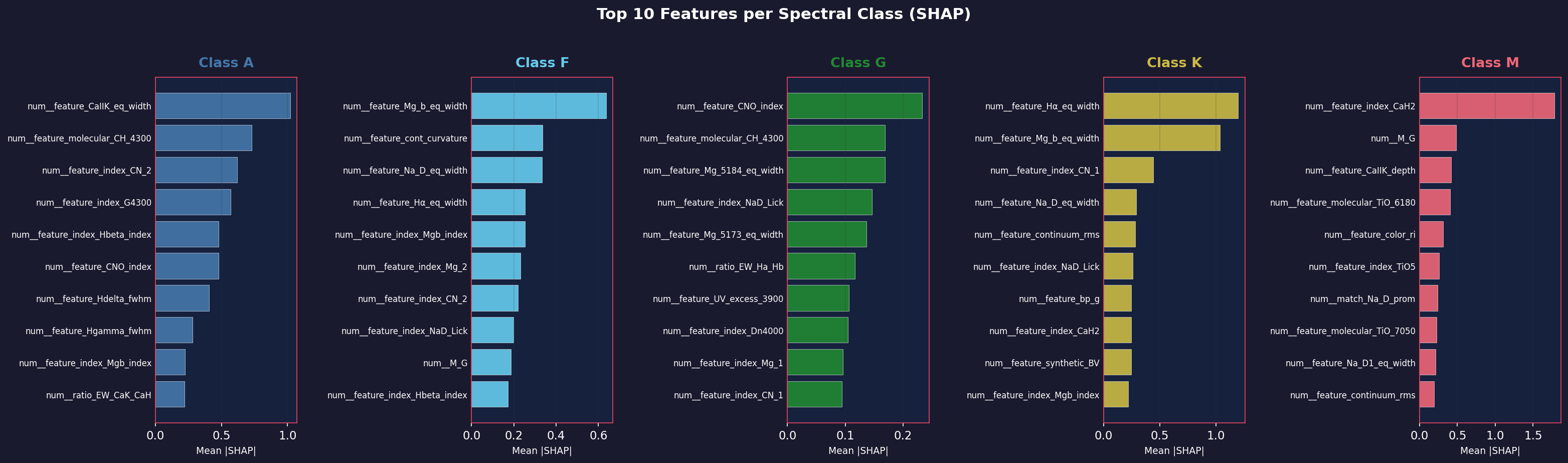
L'analyse SHAP (SHapley Additive exPlanations) sur le modèle spectro_only=True révèle que 97,9 % des 30 descripteurs les plus importants sont des features spectrales physiques. C'est la validation scientifique centrale du pipeline AstroSpectro : le modèle a appris à classifier les étoiles en utilisant exactement les mêmes informations spectroscopiques que les astrophysiciens utilisent manuellement.
⚡
Découverte clé — Ca II domine sur Balmer
Les 5 premiers descripteurs SHAP sont tous des raies Ca II H&K — la métallicité est plus discriminante que la température pour XGBoost. Contraste direct avec la PCA où la température (Balmer, PC1) domine.
Ca II (5 dans top-10)
Balmer (3 dans top-10)
Métaux (2 dans top-10)
Importance relative normalisée — run 20260213T225019Z
#
Descripteur
Importance SHAP
Famille
1
Ca II K prominence
0.98
Ca II
2
Ca II K EW
0.94
Ca II
3
Ca II K FWHM
0.91
Ca II
4
Ca II H prominence
0.87
Ca II
5
Ca II H EW
0.84
Ca II
6
Hα EW
0.76
Balmer
7
Hα prominence
0.73
Balmer
8
Mg b EW
0.68
Métaux
9
Mg b prominence
0.64
Métaux
10
Balmer temperature index
0.59
Balmer
97,9 % des 30 descripteurs les plus importants (top-30 SHAP) sont des features spectrales physiques — aucune feature non physique ne domine. Survole les barres pour voir l'interprétation de chaque descripteur.
✓ Ces deux résultats sont cohérents et complémentaires — ils répondent à deux questions différentes. La PCA répond à : «quelle est la source de variance dominante ?» → la température. XGBoost répond à : «quelle information sépare le mieux les classes ?» → la métallicité via Ca II. Le fait que les deux approches, supervisée et non supervisée, convergent vers la même structure physique confirme la validité des 183 descripteurs.
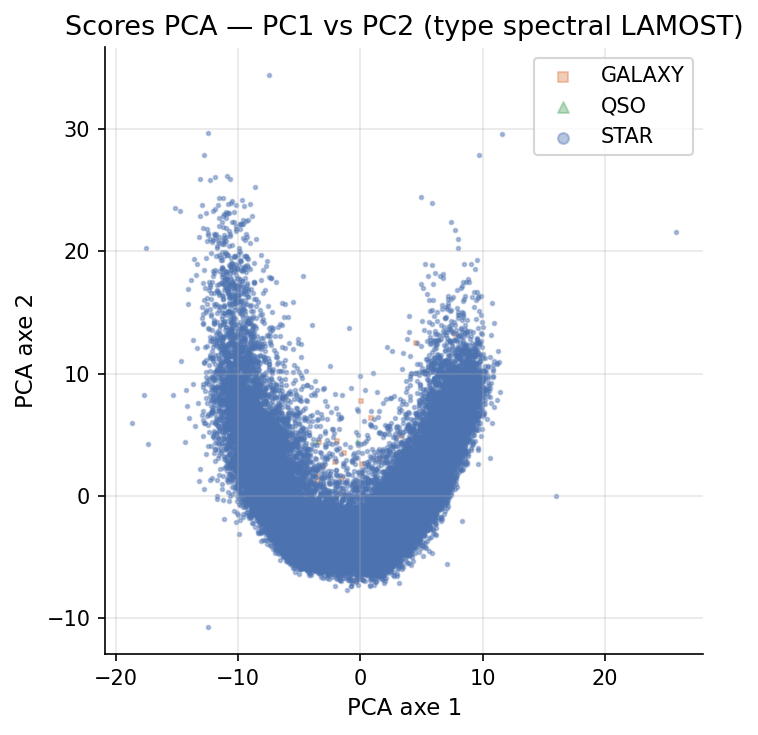
Déséquilibre de classes : Galaxies (56) et QSO (7) sont trop rares pour l'analyse HDBSCAN et ne sont pas intégrés à la classification 5 classes.
Dimensionnalité intrinsèque : Les 91 composantes nécessaires pour 95 % de variance indiquent que la variété spectrale est réellement haute-dimensionnelle. La projection 2D est une compression extrême (183 → 2), et l'émergence de la séquence de Harvard dans ces deux dimensions est un résultat non trivial.
Prochaines étapes :
Caractérisation des 20 clusters HDBSCAN par croisement avec des catalogues d'objets rares (étoiles variables, géantes RGB, binaires spectrales)
Optimisation Optuna à grande échelle sur l'ensemble des ~139k fichiers FITS disponibles
![Ca II K prominence vs [Fe/H]](/AstroSpectro/img/dimred/caIIK_prom_vs_mh.png)