Guide : Prétraitement des Spectres
Un spectre brut issu du télescope LAMOST n'est pas directement exploitable pour le machine learning. Chaque spectre encode à la fois la physique réelle de l'étoile et des artefacts instrumentaux : variations de brillance absolue entre étoiles, bruit photonique, pixels cosmiques, différences de conditions d'observation. Le prétraitement est l'étape qui élimine ces biais tout en préservant l'information physique pertinente.
Toute la logique de prétraitement est encapsulée dans SpectraPreprocessor. L'orchestration est assurée par spectra_manager.py qui applique le pipeline en parallèle sur les ~250 000 spectres téléchargés.
Vue d'ensemble du pipeline
Le pipeline de prétraitement se déroule en cinq étapes séquentielles, de la lecture du fichier FITS brut jusqu'au vecteur de 183 descripteurs prêt pour l'entraînement. Cliquer sur chaque étape pour voir les détails.
Étape 1 — Reconstruction de la grille de longueurs d'onde
La grille λ n'est pas stockée explicitement dans les fichiers LAMOST : elle doit être reconstruite depuis les métadonnées de l'en-tête FITS. Le SpectraPreprocessor implémente une chaîne de fallback robuste pour gérer les différentes conventions utilisées selon la campagne d'observation.
# Méthode primaire — COEFF0 + COEFF1 (log-linéaire) coeff0 = header['COEFF0'] # λ₀ du premier pixel (log10) coeff1 = header['COEFF1'] # pas logarithmique / pixel n_pix = flux.shape[0] # 3921 canaux loglam = coeff0 + np.arange(n_pix) * coeff1 wavelength = 10 ** loglam # → Ångströms [3690 ... 9100]
Résultat : un vecteur de 3 921 longueurs d'onde couvrant 3 690–9 100 Å, avec un pas logarithmique de Δlog(λ) ≈ 0,0001 (soit ~1,36 Å/pixel à 5 500 Å).
Étape 2 — Normalisation du flux
Les étoiles ont des brillances absolues et des distances très différentes — une étoile type A à 500 pc peut avoir un flux apparent 1 000 fois plus élevé qu'une naine M voisine. Sans normalisation, ces différences de magnitude dominent les features et masquent les différences de type spectral.
if median > 0: flux /= medianPourquoi la normalisation par la médiane suffit
La normalisation médiane est délibérément simple : elle répond à la question «ce continuum est-il au-dessus ou en dessous de son niveau moyen ?» sans tenter de modéliser la forme du continuum. Cette simplicité est une force :
- Robustesse — insensible aux raies d'émission et aux artefacts
- Reproductibilité — un seul paramètre, aucun choix arbitraire
- Équité entre descripteurs — le StandardScaler appliqué ensuite à la matrice de features achève la normalisation statistique (moyenne 0, variance 1)
# Extrait de SpectraPreprocessor.normalize_spectrum()
def normalize_spectrum(self, flux: np.ndarray) -> np.ndarray:
"""Normalise le flux par la médiane — robuste aux outliers."""
positive_flux = flux[flux > 0]
if len(positive_flux) == 0:
return flux # spectre entièrement masqué — retourner tel quel
median_flux = np.median(positive_flux)
if median_flux > 0:
return flux / median_flux
return flux
Étape 3 — Ajustement du continuum pour les pentes
Pour extraire les pentes locales du continuum (Famille 6 — ~65 descripteurs), une étape supplémentaire de sigma-clipping est appliquée localement dans chaque fenêtre spectrale :
from astropy.stats import sigma_clip
def fit_local_slope(wavelength, flux, wl_min, wl_max, sigma=2.5):
"""
Ajustement linéaire sigma-clippé du continuum local.
σ = 2,5 élimine les raies d'absorption sans biaiser la pente.
"""
mask = (wavelength >= wl_min) & (wavelength <= wl_max)
wl_local = wavelength[mask]
fl_local = flux[mask]
# Sigma-clipping — élimine les raies et les artefacts
clipped = sigma_clip(fl_local, sigma=sigma, maxiters=3)
# Régression linéaire sur le continuum propre
coeffs = np.polyfit(wl_local[~clipped.mask], fl_local[~clipped.mask], deg=1)
return coeffs[0] # pente en unités flux/Å
Cinq pentes sont extraites : UV (3800–4200 Å), visible vert (4500–5500 Å), visible rouge (5500–6500 Å), proche IR (6500–7500 Å), et pente globale (3800–7500 Å).
Les courbures locales (dérivée seconde Savitzky-Golay) suivent le même principe :
from scipy.signal import savgol_filter
def compute_curvature(flux, wavelength, center_wl, window=50, polyorder=3):
"""Courbure du continuum (dérivée seconde) en Ångströms⁻²."""
idx = np.argmin(np.abs(wavelength - center_wl))
window_pts = min(window, idx, len(flux) - idx - 1)
smooth = savgol_filter(flux, window_length=2*window_pts+1, polyorder=polyorder, deriv=2)
return smooth[idx]
Étape 4 — Filtres qualité
Deux filtres séquentiels garantissent que seuls les spectres exploitables scientifiquement entrent dans l'analyse :
Filtre 1 — Rapport signal/bruit
# SNR dans la bande rouge LAMOST (~6000–7000 Å)
mask_snr = catalog['snr_r'] > 10
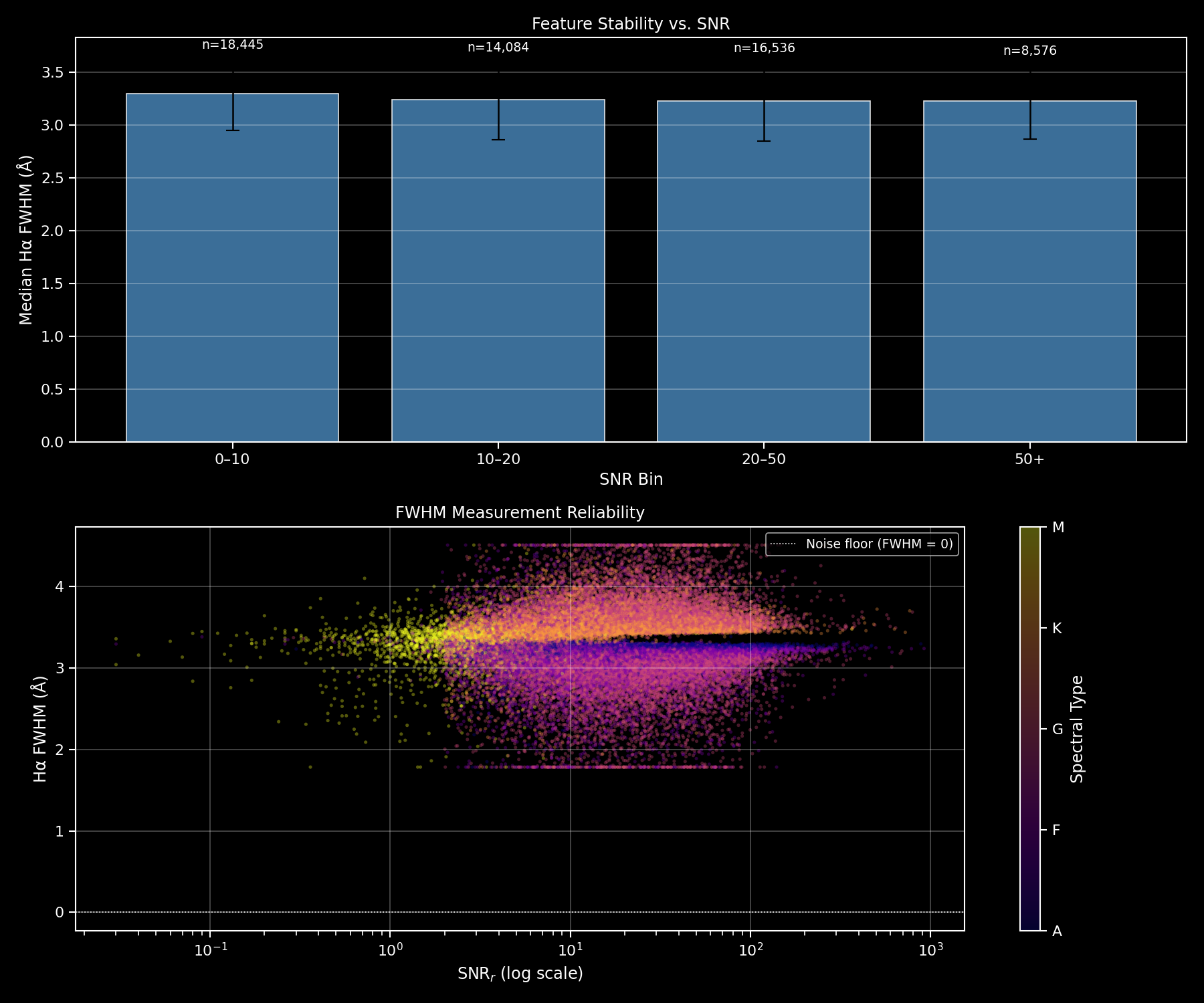
Justification : En dessous de SNR = 10, la prominence des raies faibles (Fe, Mg b) devient comparable au bruit — les descripteurs seraient dominés par des artefacts statistiques. Le seuil de 10 est le minimum pour que les mesures de largeur équivalente soient fiables.
Filtre 2 — Qualité astrométrique RUWE (Gaia DR3)
# RUWE (Re-normalised Unit Weight Error) — qualité solution astrométrique Gaia
mask_ruwe = catalog['ruwe'] < 1.4
Justification : RUWE > 1,4 indique une solution de mouvement propre défaillante — typiquement une étoile double non résolue ou un artefact de mesure. Les étoiles doubles ont des spectres composites qui brouillent les raies de classification.
Impact des filtres
| Étape | Spectres | Notes |
|---|---|---|
| Téléchargés | ~250 000 | Fichiers FITS bruts |
| Après SNR_r > 10 | ~180 000 | Spectres utilisables |
| Après RUWE < 1,4 | ~150 000 | Sources simples fiables |
| Après croisement Gaia 1″ | 43 019 | Jeu final avec paramètres de référence |
Étape 5 — Extraction des 183 descripteurs
Une fois le spectre normalisé et validé, FeatureEngineer.extract_features() calcule le vecteur de 183 descripteurs physiques :
from src.pipeline.feature_engineering import FeatureEngineer
fe = FeatureEngineer()
# Pour chaque spectre propre
vec = fe.extract_features(
matched_lines, # raies détectées par peak_detector.py
wavelength, # grille λ reconstruite (3921 points)
flux_norm, # flux normalisé par la médiane
invvar, # inverse de la variance (masquage des pixels)
)
# vec : np.ndarray de forme (183,)
Débit de traitement mesuré : ~340 000 spectres/heure (Ryzen 9 5950X, 32 fils, parallélisation joblib).
Figures de référence
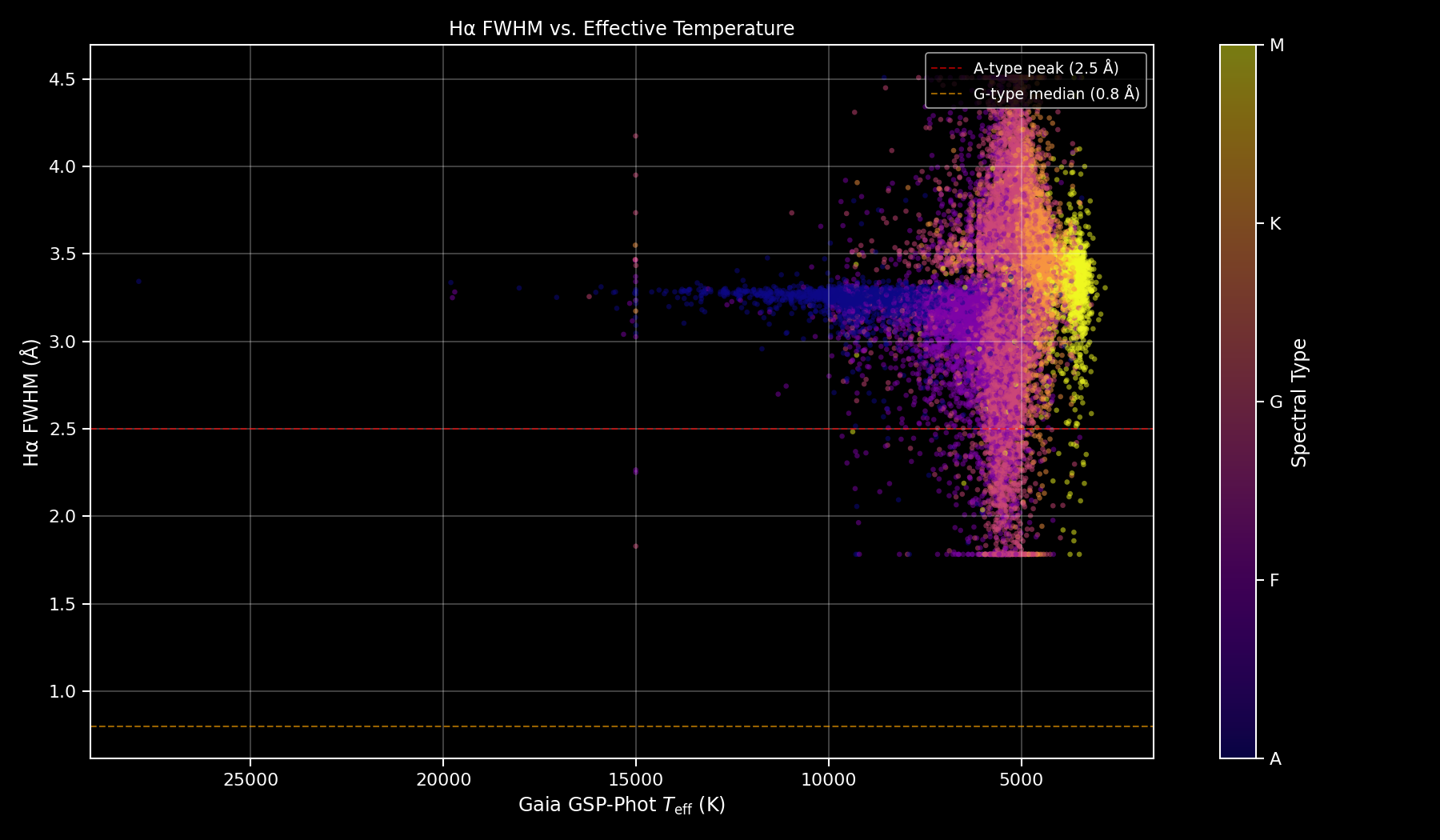
Pistes d'amélioration futures
Le prétraitement actuel est conçu pour être rapide et robuste sur les ~250 000 spectres disponibles. La Roadmap du projet prévoit :
- Ajustement polynomial du continuum — méthode iterative pour les étoiles à fort continuum UV
- Débruitage systématique — Savitzky-Golay appliqué au spectre complet avant l'extraction des raies faibles
- Correction de l'extinction interstellaire — A_G × R_V pour les étoiles à fort rougissement
- Traitement des spectres binaires — déconvolution des profils de raies composites pour les clusters C19/C1/C12 identifiés par HDBSCAN