Guide : Visualisation
La visualisation est essentielle pour comprendre les données, déboguer le pipeline et interpréter les résultats du modèle. Le projet AstroSpectro intègre une suite d'outils de visualisation avancés, principalement orchestrés par le notebook 02_tools_and_visuals.ipynb et la classe AstroVisualizer.
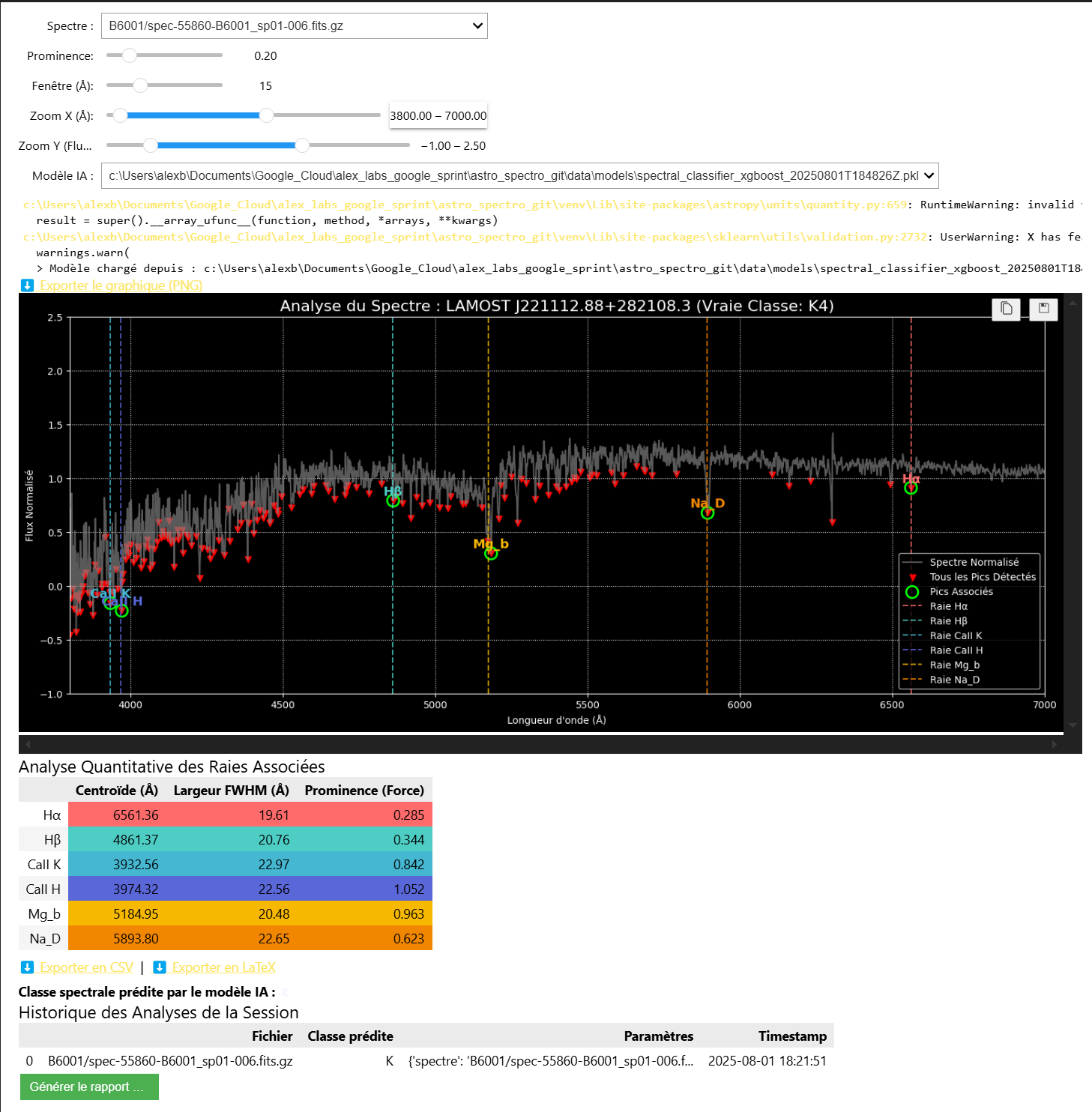
L'Analyseur de Spectre Augmenté (Outil Principal)
C'est l'outil d'exploration "tout-en-un" du projet. Accessible via le notebook 02_tools_and_visuals.ipynb, cette interface interactive vous permet de :
- Naviguer dans l'ensemble des spectres téléchargés.
- Ajuster en temps réel les paramètres de détection de pics (
prominence,window). - Visualiser l'impact de ces paramètres sur la détection des raies (cercles verts).
- Obtenir une prédiction de classe spectrale en direct en sélectionnant un modèle IA entraîné.
- Consulter une analyse quantitative des raies détectées (Centroïde, FWHM, Force).
- Exporter les graphiques (PNG) et les analyses (CSV, LaTeX).
- Générer un rapport HTML complet de votre session d'analyse.
L'image ci-dessous montre l'interface complète en action. On peut y voir le spectre, les paramètres de tuning, le modèle IA sélectionné, le graphique avec les raies détectées, le tableau d'analyse et l'historique de la session.
L'application est hébergée sur Streamlit Community Cloud et est accessible directement ci-dessous.
C'est une version simplifié de ce qui se trouve dans le notebook 02_tools_and_visuals.
Cette application est construite avec Streamlit et utilise le module visualizer.py de notre projet. Elle est déployée automatiquement depuis la branche deploy-streamlit de notre dépôt GitHub.
Autres Outils de Visualisation
Le notebook 02_tools_and_visuals.ipynb contient également d'autres outils de diagnostic spécialisés.
Tableau de Bord de l'État du Dataset
Affiche des statistiques clés sur votre collection de données : nombre total de spectres, nombre déjà utilisés pour l'entraînement, et nombre de nouveaux spectres disponibles.
Explorateur de Header FITS
Une interface interactive pour naviguer et afficher le contenu complet de l'en-tête (header) de n'importe quel fichier FITS de votre collection.
Analyse de la Qualité des Features
Cet outil charge le dernier fichier de features généré et affiche un graphique à barres montrant le pourcentage de valeurs nulles pour chaque feature. C'est un outil crucial pour diagnostiquer les problèmes d'extraction.
Carte de Couverture Céleste
Génère une carte du ciel en projection Mollweide montrant la position de tous les plans d'observation que vous avez téléchargés. La taille et la couleur des points indiquent la densité de spectres par plan.
Inspecteur de Modèles Entraînés
Permet de sélectionner n'importe quel modèle .pkl sauvegardé et d'afficher ses hyperparamètres optimisés ainsi qu'un graphique de l'importance de chaque feature pour ses prédictions.
Comparateur de Spectres Interactif
Un outil pour superposer plusieurs spectres sur un même graphique, avec des options de normalisation et de décalage vertical pour faciliter la comparaison visuelle.