Anatomie d'une Amélioration
Une étude de cas sur la manière dont une meilleure extraction de features, guidée par des outils de visualisation, a permis d'augmenter la performance d'un modèle de 75% par rapport à sa baseline.
J'ai construit un pipeline qui modélise la classification spectrale en se basant sur les principes de la physique stellaire. Le modèle a appris de manière autonome que les ratios de force des raies du Calcium et de l'Hydrogène sont les meilleurs indicateurs de température, ce qui valide notre approche de feature engineering et nous a permis d'atteindre une précision de 56%.
Aujourd'hui, après plusieurs itérations de débogage, d'analyse et d'optimisation, nous avons franchi une étape significative, faisant passer la précision du modèle de 32% à un très respectable 56%. Voici le récit de cette progression.
Itération 1 : De la Présence à la Force des Raies
La première amélioration consistait à passer d'une feature binaire (la raie est-elle présente ?) à une mesure continue : la force de la raie, approximée par la "prominence" du pic d'absorption. Ce changement a eu un impact immédiat, faisant grimper notre précision globale de 32% à 40%. Cette étape a validé que la quantité d'information physique contenue dans la force d'une raie était bien plus riche que sa simple présence.
Voir les résultats en détail
Suppression des classes trop rares : ['C']
Features utilisées pour l'entraînement : ['feature_Hα', 'feature_Hβ', 'feature_CaIIK', 'feature_CaIIH']
Nombre d'échantillons : 4999, Nombre de features : 4
> Entraînement du modèle sur 3749 échantillons...
> Modèle entraîné.
--- Rapport d'Évaluation ---
precision recall f1-score support
A 0.58 0.64 0.61 73
B 0.00 0.00 0.00 1
D 0.00 0.00 0.00 1
F 0.43 0.43 0.43 255
G 0.43 0.35 0.38 394
K 0.34 0.49 0.40 283
M 0.28 0.18 0.22 158
N 0.43 0.51 0.46 84
W 0.00 0.00 0.00 1
s 0.00 0.00 0.00 0
accuracy 0.40 1250
macro avg 0.25 0.26 0.25 1250
weighted avg 0.40 0.40 0.40 1250
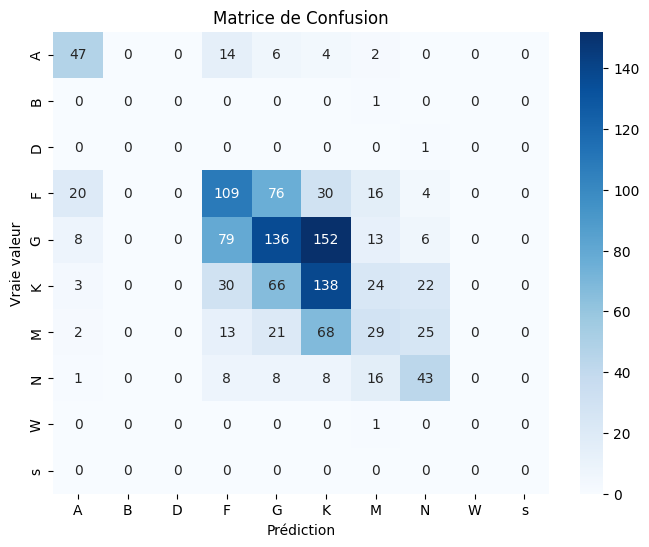
Itération 2 : La Puissance des Ratios Spectraux
Avec une nouvelle baseline solide, nous avons introduit des features encore plus sophistiqués : les ratios de force entre différentes raies. En astrophysique, ces ratios sont des indicateurs de température extrêmement puissants.
feature_ratio_CaK_Hbeta = CaII K / Hβfeature_ratio_Halpha_Hbeta = Hα / Hβ
L'ajout de ces deux seuls ratios a de nouveau propulsé notre modèle, atteignant une précision de 50%. La matrice de confusion montrait une nette amélioration, mais une analyse de la qualité des features a révélé une faiblesse critique : la raie Hα était absente dans plus de 50% des spectres, rendant les ratios peu fiables.
Voir les résultats en détail
--- Chargement du dataset : features_20250723T225208Z.csv ---
> 250 lignes avec des labels invalides ou nuls supprimées.
> Suppression des classes trop rares : ['W', 'C', 'D', 'B', 's']
Features utilisées : ['feature_Hα', 'feature_Hβ', 'feature_CaIIK', 'feature_CaIIH', 'feature_ratio_CaK_Hbeta', 'feature_ratio_Halpha_Hbeta']
Nombre d'échantillons final : 2740, Nombre de features : 6
--- ÉTAPE 5: Entraînement et Évaluation du modèle ---
> Entraînement du modèle sur 2055 échantillons...
> Modèle entraîné.
--- Rapport d'Évaluation ---
precision recall f1-score support
A 0.70 0.51 0.59 41
F 0.54 0.60 0.57 157
G 0.55 0.58 0.56 230
K 0.41 0.40 0.41 163
M 0.34 0.29 0.31 94
accuracy 0.50 685
macro avg 0.51 0.48 0.49 685
weighted avg 0.49 0.50 0.49 685
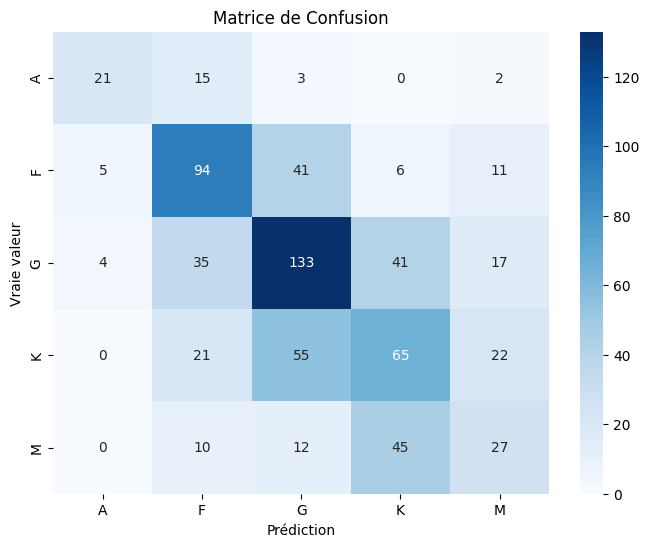
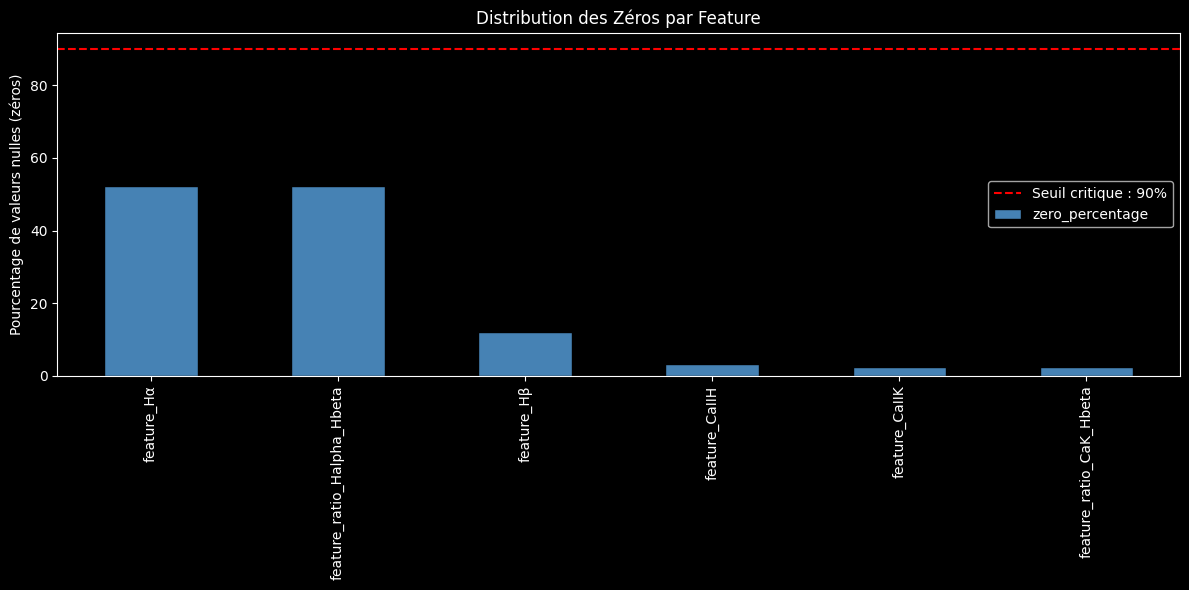
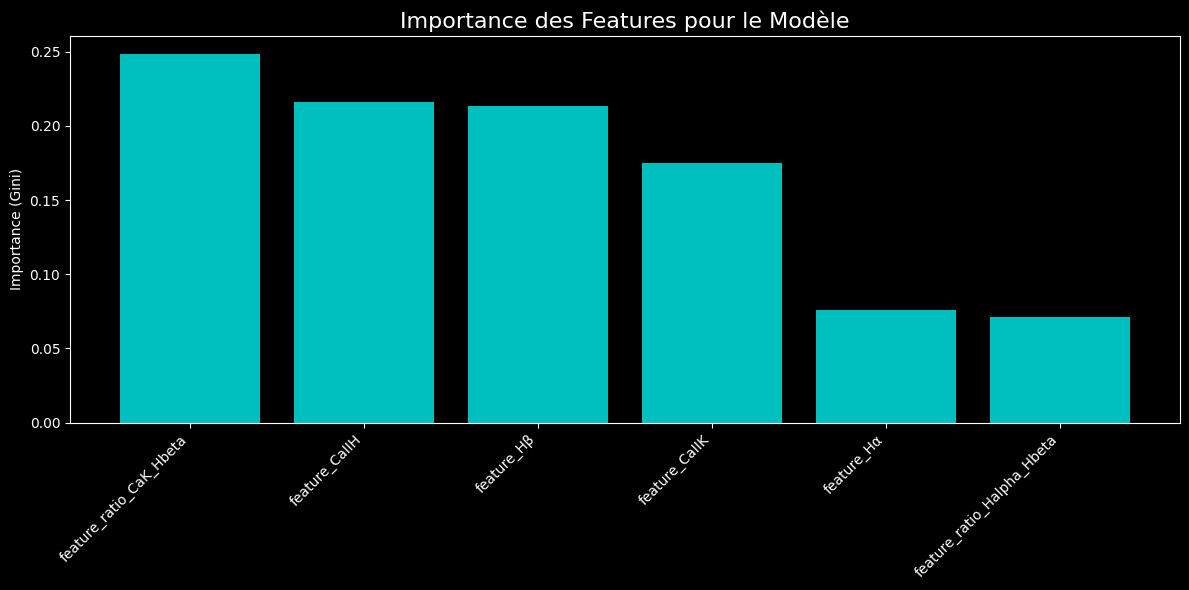
Itération Finale : Le Tuning par la Visualisation
C'est à ce stade que nos outils de visualisation sont devenus cruciaux. L'analyse a montré que notre paramètre de détection de pics (prominence) était trop strict et ignorait de nombreuses raies réelles mais moins profondes.
Grâce à notre analyseur de spectre interactif, nous avons pu "tuner" ce paramètre en temps réel. Une valeur optimisée de prominence=0.23 a été identifiée, permettant de récupérer un grand nombre de raies auparavant ignorées.
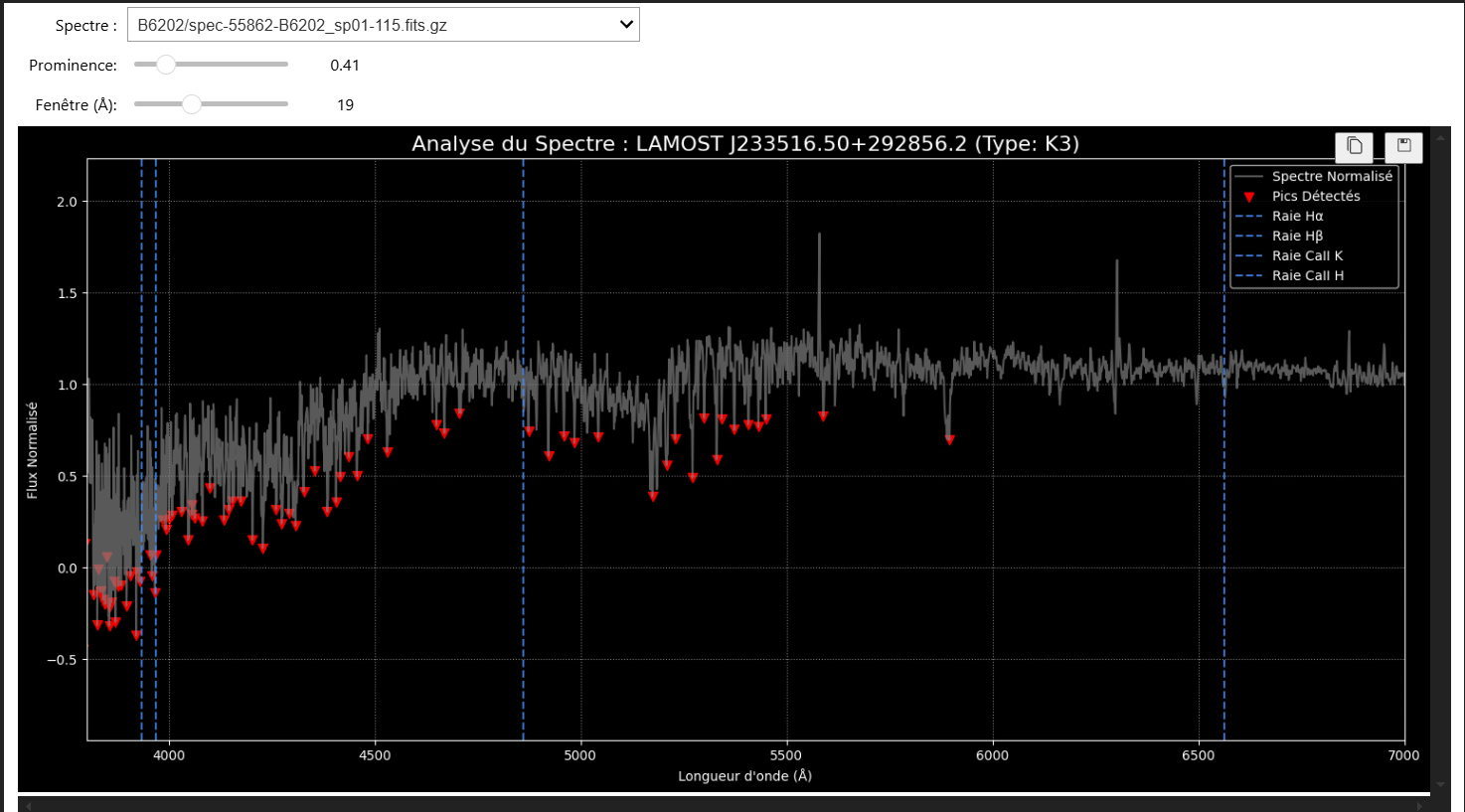
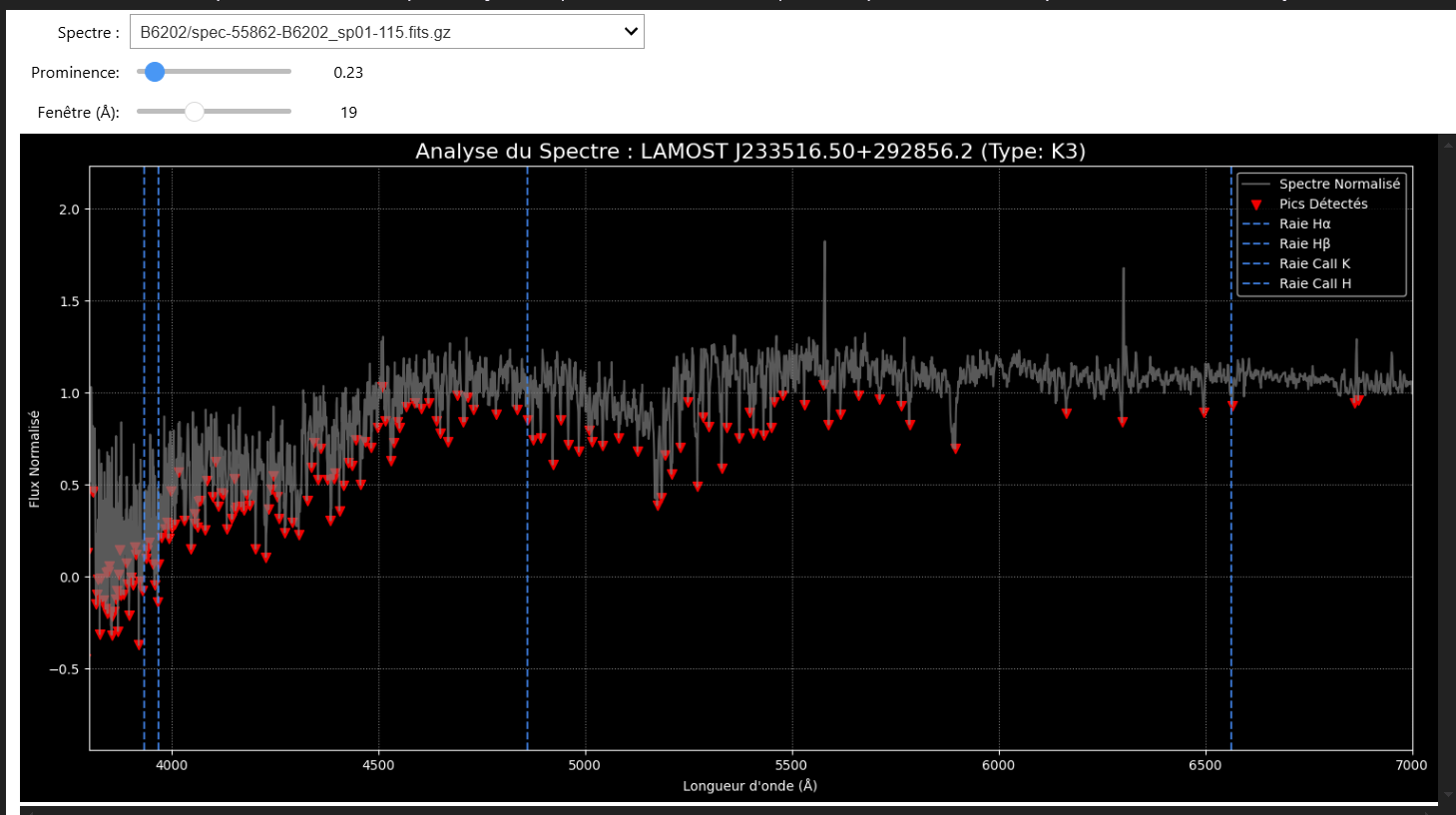
Le Résultat Final : Une Précision de 56%
Après avoir relancé le pipeline complet avec ce paramètre optimisé sur un nouveau lot de 2607 spectres, les résultats ont dépassé nos attentes :
- Précision Globale : 56%
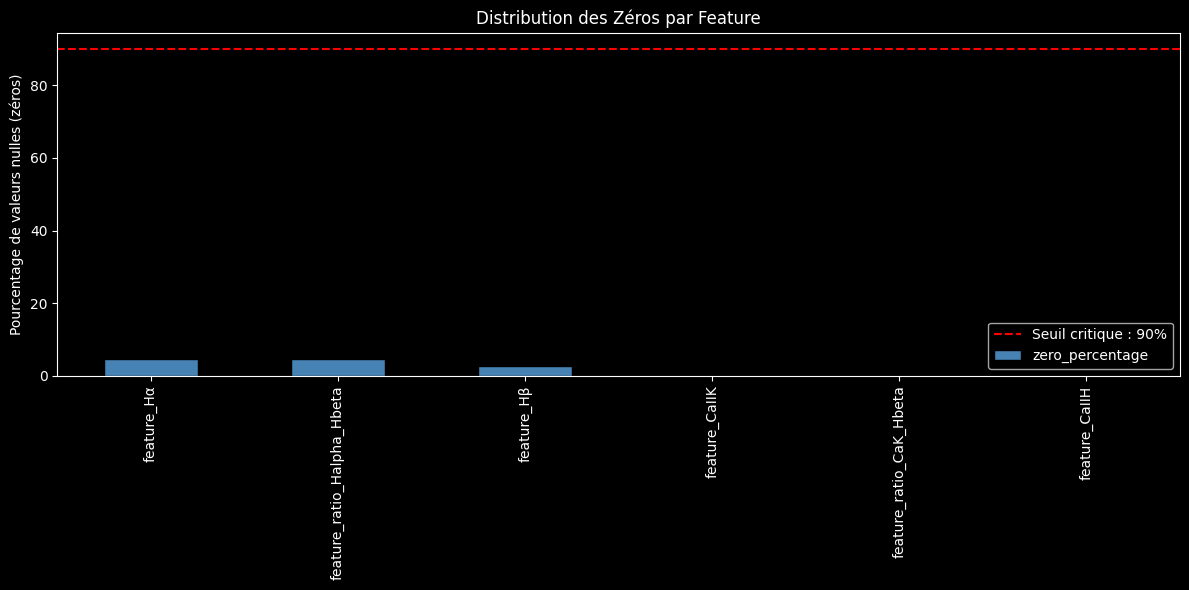
- Qualité des Features : Le problème des valeurs manquantes a été quasiment éliminé, avec toutes les features de base présentes dans plus de 95% des cas.
- Pertinence des Features : L'importance des features est maintenant bien mieux équilibrée.
feature_Hβet leratio_CaK_Hbetas'imposent comme les indicateurs les plus puissants, mais toutes les features contribuent désormais de manière significative.
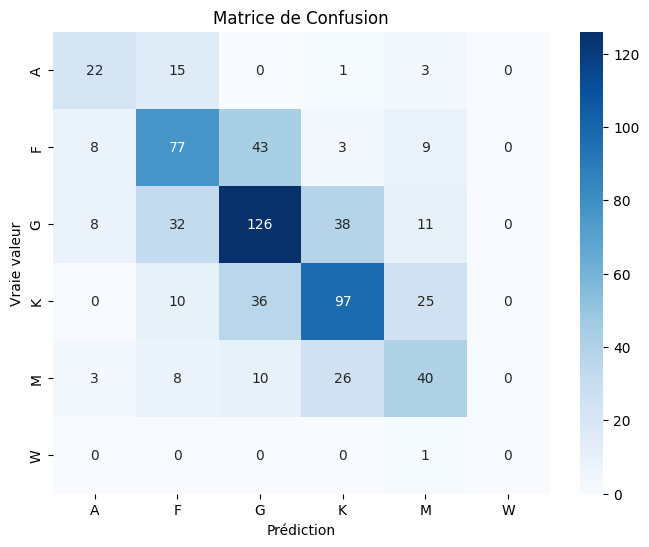
La matrice de confusion finale montre une diagonale bien plus nette, signe d'un modèle plus confiant et plus précis, avec des scores F1 supérieurs à 0.54 pour toutes les classes principales.
Voir les résultats en détail
--- Chargement du dataset : features_20250724T012617Z.csv ---
> 383 lignes avec des labels invalides ou nuls supprimées.
> Suppression des classes trop rares : ['s', 'B', 'D', 'C']
Features utilisées : ['feature_Hα', 'feature_Hβ', 'feature_CaIIK', 'feature_CaIIH', 'feature_ratio_CaK_Hbeta', 'feature_ratio_Halpha_Hbeta']
Nombre d'échantillons final : 2607, Nombre de features : 6
--- ÉTAPE 5: Entraînement et Évaluation du modèle ---
> Entraînement du modèle sur 1955 échantillons...
> Modèle entraîné.
--- Rapport d'Évaluation ---
precision recall f1-score support
A 0.54 0.54 0.54 41
F 0.54 0.55 0.55 140
G 0.59 0.59 0.59 215
K 0.59 0.58 0.58 168
M 0.45 0.46 0.45 87
W 0.00 0.00 0.00 1
accuracy 0.56 652
macro avg 0.45 0.45 0.45 652
weighted avg 0.55 0.56 0.56 652
Conclusion et Prochaines Aventures
Ce sprint de recherche a été une démonstration éclatante de la puissance de la méthode itérative en science des données. En partant d'un modèle simple, et en l'améliorant étape par étape en se basant sur l'analyse des résultats, nous avons amélioré notre baseline de 24 points de pourcentage.
Le projet AstroSpectro dispose maintenant d'un pipeline de production robuste et d'une suite d'outils d'analyse performants. Les prochaines pistes d'exploration sont déjà sur la table :
- Enrichir les features pour mieux classifier les étoiles froides (type M) en ajoutant des bandes moléculaires.
- Expérimenter avec des modèles plus puissants comme XGBoost ou des réseaux de neurones.
- Passer au Deep Learning en utilisant le spectre entier comme entrée d'un réseau de neurones convolutifs (CNN).
Le laboratoire est construit. Les outils sont affûtés. L'aventure continue ! 🚀